Notas de la instructora
Soluciones a desafíos
Instalar los paquetes requeridos para el taller
Por favor sigue las instrucciones del documento Setup para instalar los programas necesarios para esta lección. Si encuentras problemas, por favor crea un issue con la etiqueta High-priority.
Revisando instalaciones
En el directorio _includes/scripts encontrarás un
script llamado check_env.py. Éste revisa
la funcionalidad de la versión instalada de Anaconda.
Por defecto, Data Carpentry no requiere que la gente descargue el
repositorio completo con todos los scripts y apéndices. Por lo tanto,
como instructor, debes decidir cómo te gustaría proveer este script a
las estudiantes, si es que decides hacerlo. Para usarlo, las estudiantes
pueden navegar en su terminal hasta _includes/scripts y
ejecutar lo siguiente:
Si las estudiantes reciben un AssertionError, éste te
informará cómo ayudar a corregir la instalación. De lo contrario, ¡te
dirá que el sistema está listo para Data Carpentry!
01-short-introduction-to-Python
Desafíos sobre tuplas
¿Qué sucede cuando ejecutas
a_list[1] = 5?-
¿Qué sucede cuando ejecutas
a_tuple[2] = 5?Como
tuplees inmutable, no soporta asignación de ítems. Los elementos delistpueden ser alterados individualmente. -
¿Qué te dice
type(a_tuple)sobrea_tuple?tuple
Desafíos sobre diccionarios
- Cambiando diccionarios: 2. Reasigna el segundo valor.
Asegúrate también de aclarar que acceder al “segundo valor” se trata
del nombre de la clave. Agrega por ejemplo rev[10] = "ten"
para aclarar que no se trata de la posición.
SALIDA
{1: 'one', 2: 'two', 3: 'three'}SALIDA
{1: 'one', 2: 'apple-sauce', 3: 'three'}02-starting-with-data
Nota sobre bugs
Pandas < .18.1 tiene un error bug por el cual
surveys_df['weight'].describe() puede devolver un error en
tiempo de ejecución.
Desafíos sobre DataFrames
-
surveys_df.columnsNombres de columnas. (Opcional: muestra
surveys_df.columns[4] = "plotid". El índice no es mutable; recapitula del episodio anterior. La adaptación del nombre es realizada por la funciónrename:surveys_df.rename(columns={"plot_id": "plotid"})) -
surveys_df.head(). Además, ¿qué realizasurveys_df.head(15)?Muestra las primeras 5 líneas. Muestra las primeras 15 líneas.
-
surveys_df.tail()Muestra las últimas 15 líneas.
-
surveys_df.shape. Toma nota de la salida deshape- ¿Qué formato tiene la salida del atributo que regresa la forma de un DataFrame?type(surveys_df.shape)->Tuple
Desafíos sobre calcular estadísticas de los datos
-
Crear una lista de los IDs de los sitios
plot_idque están en los datos de la encuestasurveys_df. Llamemos a esta listasite_names. ¿Cuántos sitios hay en los datos?, ¿cuántas especies hay en los datos?plot_names = pd.unique(surveys_df["plot_id"]). Número de IDs de los sitios:plot_names.sizeolen(plot_names). Número de especies en los datos:len(pd.unique(surveys_df["species"])) ¿Cuál es la diferencia entre
len(plot_names)ysurveys_df['plot_id'].nunique()?
Ambos resultan en el mismo output, sirviendo como formas alternativas
de obtener los valores únicos. nunique combina el conteo
con la extracción de valores únicos.
Desafíos sobre agrupamientos
-
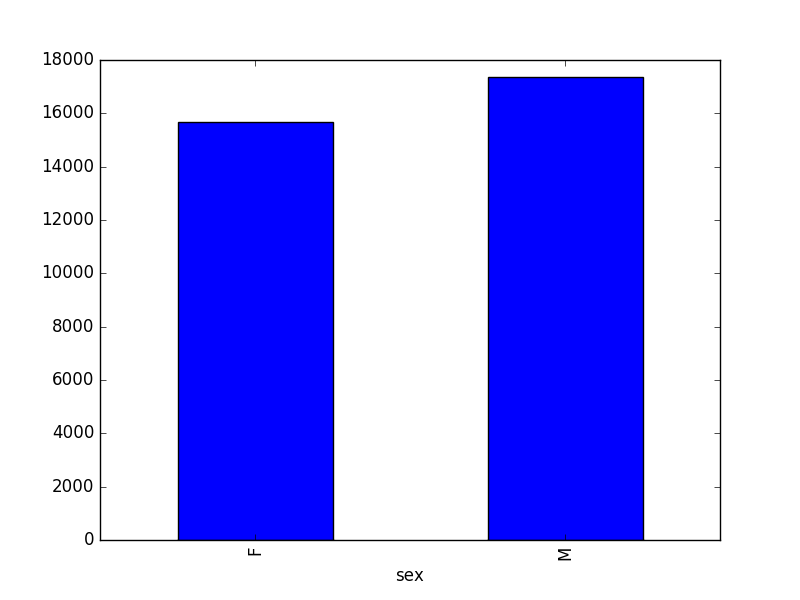
¿Cuántas observaciones son de sexo femenino
Fy cuántas de sexo masculinoM?grouped_data.count() -
¿Qué pasa cuando agrupas sobre dos columnas usando el siguiente enunciado y después tomas los valores medios?
Se calcula el valor medio para cada combinación de
plot_idysex. Remarca que la media no tiene sentido para cada variable, así que puedes especificarla por columna: por ejemplo, si deseas conocer el último año censado, la mediana de las longitudes de pies y el valor medio del peso para cada combinación deplotysex:
PYTHON
surveys_df.groupby(['plot_id','sex']).agg({"year": 'min',
"hindfoot_length": 'median',
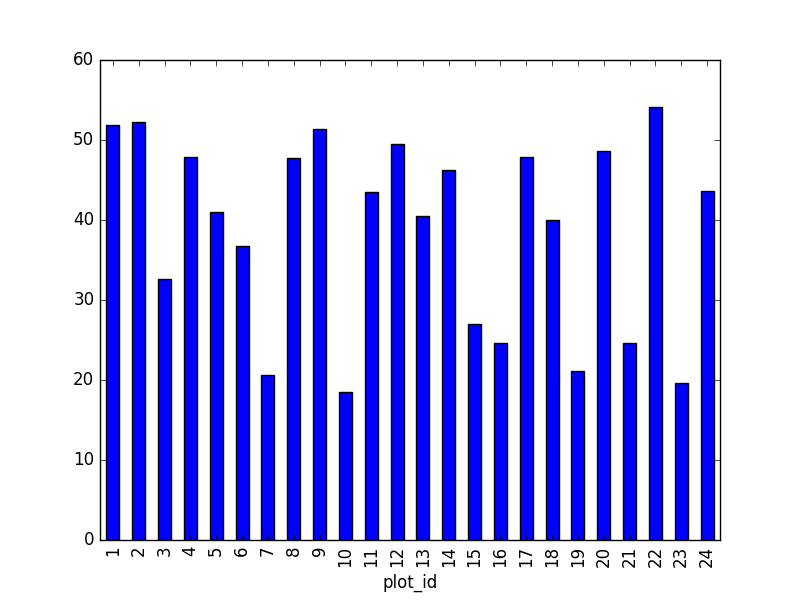
"weight": 'mean'})`- Calcula las estadísticas descriptivas del peso
weightpara cadaplot_id.
-
¿Qué otra manera hay de crear una lista de especies y asociarle el número
countde las muestras de los datos?En vez de recuperar y luego contar las columnas resultantes de
groupby, también puedes hacer el recuento junto congroupby(en todas las columnas) y construir una selección delDataFrameresultante:surveys_df.groupby('species_id').count()["record_id"]
03-index-slice-subset
Sugerencia: usa el método .head() a lo largo de esta
lección con el fin de mantener tu pantalla limpia. Anima a las
estudiantes a probar comandos con y sin .head() para
reforzar la utilidad de esta herramienta y luego emplearla, o no, según
su preferencia. Por ejemplo, si una estudiante muestra preocupación por
mantener el ritmo de tipeo, infórmale que puede evitar
.head(), pero que tú lo usarás para mantener visibles más
líneas anteriores de código.
Desafíos sobre indexación
-
¿Qué valor devuelve el siguiente código?
a[0]1, ya que Python comienza por el elemento 0 (para usuarios de Matlab: ¡esto es diferente!) -
¿Qué valor devuelve éste?
a[5]IndexError -
En el ejemplo anterior, llamar a
a [5]devuelve un error. ¿Por qué?La lista no tiene ningún elemento con índice 5 (va de 0 a 4).
-
¿Qué tal éste?
a[len(a)]IndexError
Desafíos sobre rangos
-
¿Qué ocurre al ejecutar el siguiente código?
surveys_df[0:1]selecciona sólo el primer elementosurveys_df[:4]seleccionar desde el primer elemento hace redundante escribir el 0surveys_df[-1:]puedes contar hacia atrásSugerencia: También puedes seleccionar cada N-ésima fila:
surveys_df[1:10:2]. Entonces, ¿cómo interpretassurveys_df[::-1]? -
¿Qué pasa al ejecutar este otro?:
surveys_df.iloc[0:4, 1:4]ysurveys_df.loc[0:4, 1:4]? ¿Qué diferencia observas entre los resultados de los comandos inmediatamente anteriores?Revisa la posición, o el nombre. La segunda opción se asemeja a consultar un diccionario por nombres de llaves. Los nombres de columnas 1:4 no existen, resultando en un error. Revisa también la diferencia entre
surveys_df.loc[0:4]ysurveys_df.iloc[0:4]
Desafíos avanzados sobre queries
-
Selecciona un subconjunto de filas, en el
DataFramesurveys_df, que contenga datos desde el año 1999 y que contenga valores enweightmenores o iguales a 8. ¿Cuántas filas obtuviste como resultado? ¿Cuántas filas obtuvo tu compañera?surveys_df[(surveys_df["year"] == 1999) & (surveys_df["weight"] <= 8)]; cuándo sólo te interesa el número final, también puede utilizarse la suma de valoresTrue:sum((surveys_df["year"] == 1999) & (surveys_df["weight"] <= 8)) -
Puedes usar la función
isinde Python para hacer una consulta, a unDataFrame, basada en una lista de valores según se muestra a continuación:surveys_df[surveys_df['species_id'].isin([listGoesHere])]. Usa la funciónisinpara encontrar todos losplotsque contienen una especie en particular en elDataFramesurveys_df. ¿Cuántos registros contienen esos valores?Por ejemplo, usa
PByPL:surveys_df[surveys_df['species_id'].isin(['PB', 'PL'])]['plot_id'].unique()provee una lista de todos los gráficos en los que están involucradas estas especies. Consurveys_df[surveys_df['species_id'].isin(['PB', 'PL'])].shapese puede obtener el número de registros. -
Experimenta con otras consultas. Crea una consulta que encuentre todas las filas con el valor de
weightmayor o igual a 0.surveys_df[surveys_df["weight"] >= 0]Sugerencia: Puedes presentar aquí que todas estas operaciones de segmentación se basan realmente en operaciones de indexado booleano (la siguiente sección en esta lección). El filtrado indica para cada registro si éste satisface (
True) o no (False) una condición. La segmentación se realiza por interpretación del valorTrue/Falsode cada registro. El símbolo
~en Python puede ser usado para obtener lo opuesto a los datos seleccionados que hayas especificado en Python. Es equivalente a no esta en. Escribe una consulta que seleccione todas las filas consexdiferente de ‘M’ o ‘F’ en los datos desurveys.
Desafíos sobre máscaras
- Crea un nuevo objeto
DataFrameque solamente contenga observaciones cuyos valores en la columnasexno seanfemaleomale. Asigna cada valor desexen el nuevoDataFramea un nuevo valor de ‘x’. Determina el número total de valoresnullen el subconjunto.
Puedes verificar el número de valores Nan con
sum(surveys_df['sex'].isnull()), que resulta igual al
número de registros que no son female ni
male.
- Crea un nuevo objeto
DataFrameque contenga solo observaciones cuyos valores en la columnasexseanmaleofemaley en los cuales el valor deweightsea mayor que 0. Luego, crea un gráfico de barra apiladas del promedio deweight, por parcela, con valoresmaleversusfemaleapilados por cada parcela.
PYTHON
# selecciona los datos con isin:
stack_selection = surveys_df[(surveys_df['sex'].isin(['M', 'F'])) &
surveys_df["weight"] > 0.][["sex", "weight", "plot_id"]]
# calcula el promedio de weight para cada combinación de plot_id y sex:
stack_selection = stack_selection.groupby(["plot_id", "sex"]).mean().unstack()
# podemos representarlo como un gráfico de barras apiladas:
stack_selection.plot(kind='bar', stacked=True)Sugerencia: Como sabemos que todos los otros valores son
Nan, podemos seleccionar también todos los valores que no sean
null (esto es sólo un vistazo previo, habrá más al respecto
en la siguiente lección):
PYTHON
stack_selection = surveys_df[(surveys_df['sex'].notnull()) &
surveys_df["weight"] > 0.][["sex", "weight", "plot_id"]]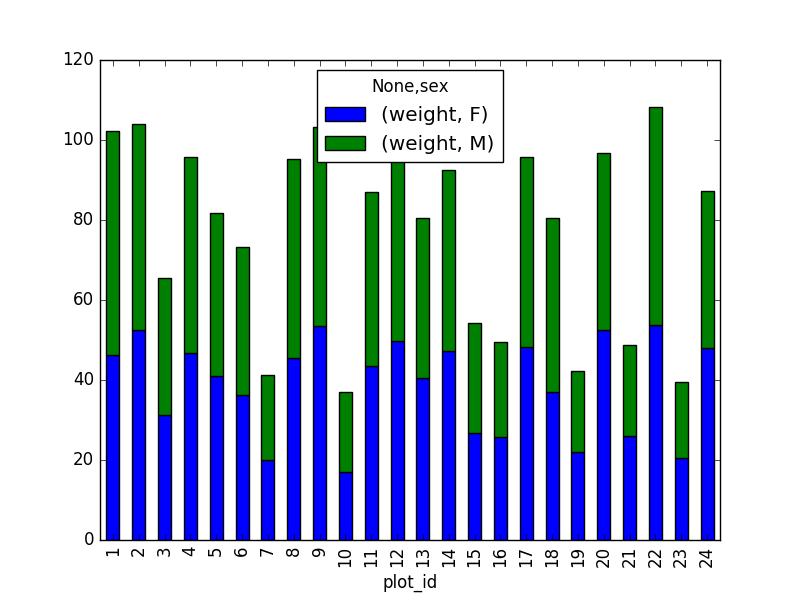
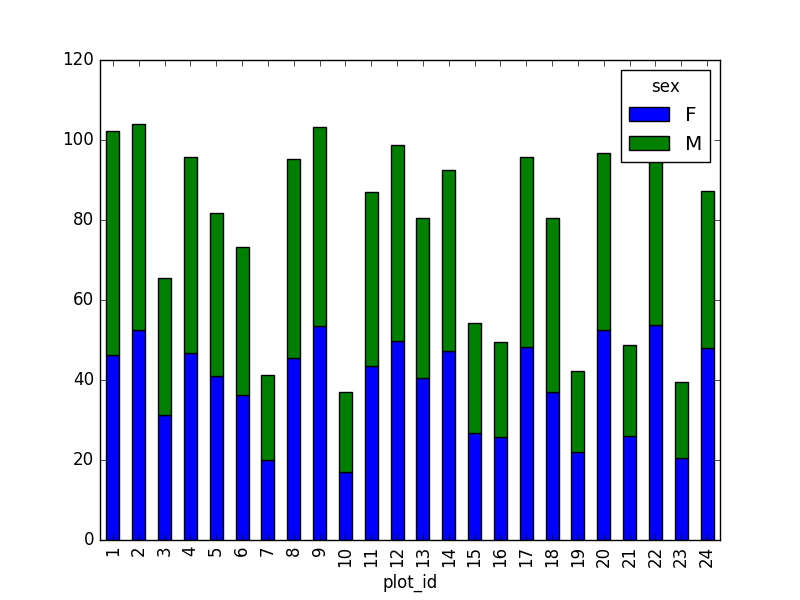
Sin embargo, debido al comando unstack, el encabezado de
la leyenda contiene dos niveles. Para removerlo, los nombres de columnas
deben ser simplificados:
04-data-types-and-format
Desafíos sobre cambiar tipos
- Intenta convertir la columna
plot_ida float usandosurveys_df.plot_id.astype("float"). A continuación, intenta convertirweight(peso) en un integer. ¿Qué te dice Pandas? ¿Qué es lo que va mal ahí?
Pandas no puede convertir datos de tipo float a int si la columna contiene valores NaN.
Desafíos sobre cuentas
- Cuenta el número de valores perdidos por columna. Sugerencia: el
método
.count()te proporciona el número de observaciones que no son NA por columna. Examina el método.isnull().
Si las estudiantes tienen problemas para generar el output, u ocurre algo con éste, existe un archivo llamado “sample output” con los datos que ellas deben generar.
05-merging-data
- En la carpeta de datos, hay dos archivos de datos de encuestas:
survey2001.csvysurvey2002.csv. Lee los datos en Python y combina los archivos para hacer un DataFrame nuevo. Crea una gráfica del peso promedio de la parcela,plot_id, por año agrupada porsex. Exporta tus resultados como CSV y asegúrate de que se lean correctamente en Python..
PYTHON
# lee los archivos:
survey2001 = pd.read_csv("data/survey2001.csv")
survey2002 = pd.read_csv("data/survey2002.csv")
# concatena los archivos:
survey_all = pd.concat([survey2001, survey2002], axis=0)
# recupera el peso de cada año, agrupado por sexo:
weight_year = survey_all.groupby(['year', 'sex']).mean()["wgt"].unstack()
# genera el gráfico:
weight_year.plot(kind="bar")
plt.tight_layout() # tip(!)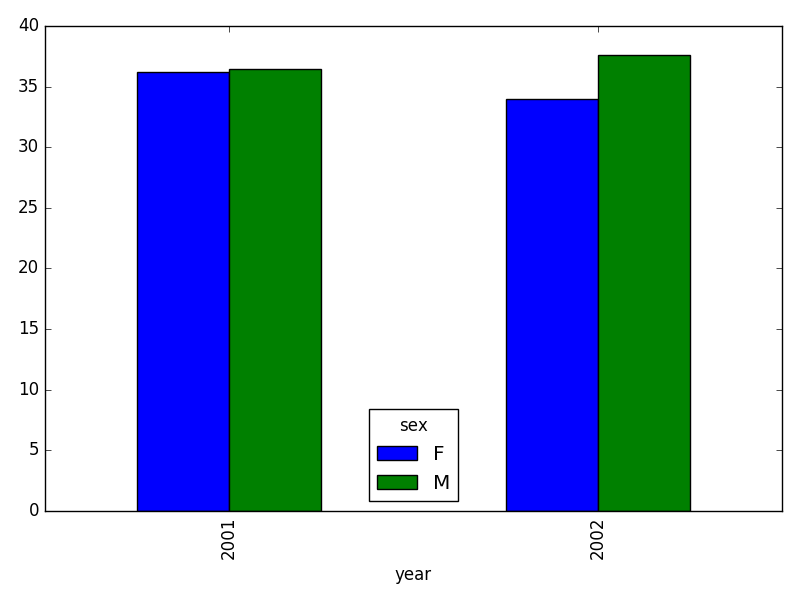
PYTHON
# escribe a un archivo:
weight_year.to_csv("weight_for_year.csv")
# lee los datos de nuevo:
pd.read_csv("weight_for_year.csv", index_col=0)- Cree un nuevo DataFrame uniendo los contenidos de las tablas
surveys.csvyspecies.csv.
Luego calcula y crea un gráfico de la distribución de:
1. taxa por parcela (número de especies de cada taxa por parcela):
La distribución de especies (número de taxa por cada parcela) puede calcularse de la siguiente forma:
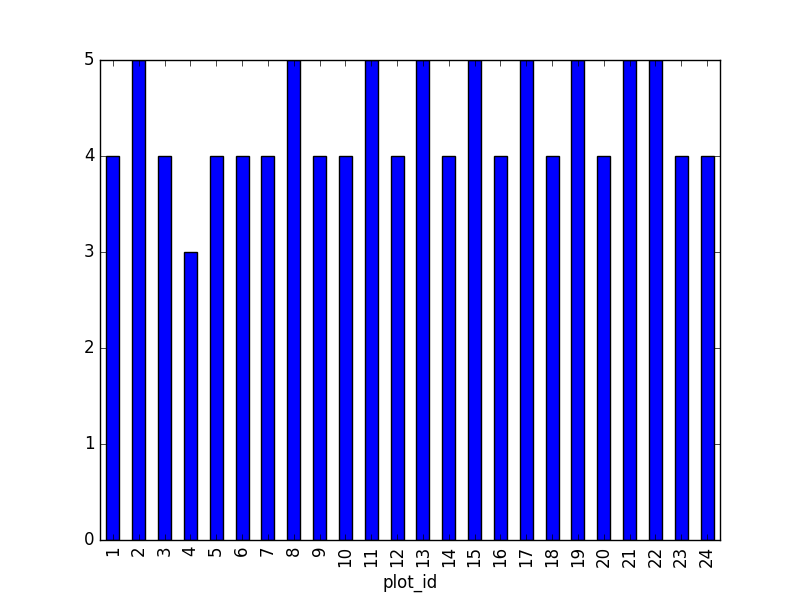
Sugerencia: También es posible graficar el número de invididuos de cada taxa en cada parcela (gráfico de barras apiladas):
PYTHON
merged_left.groupby(["plot_id", "taxa"]).count()["record_id"].unstack().plot(kind='bar', stacked=True)
plt.legend(loc='upper center', ncol=3, bbox_to_anchor=(0.5, 1.05))(de otro modo, la leyenda se superpone con el gráfico de barras)
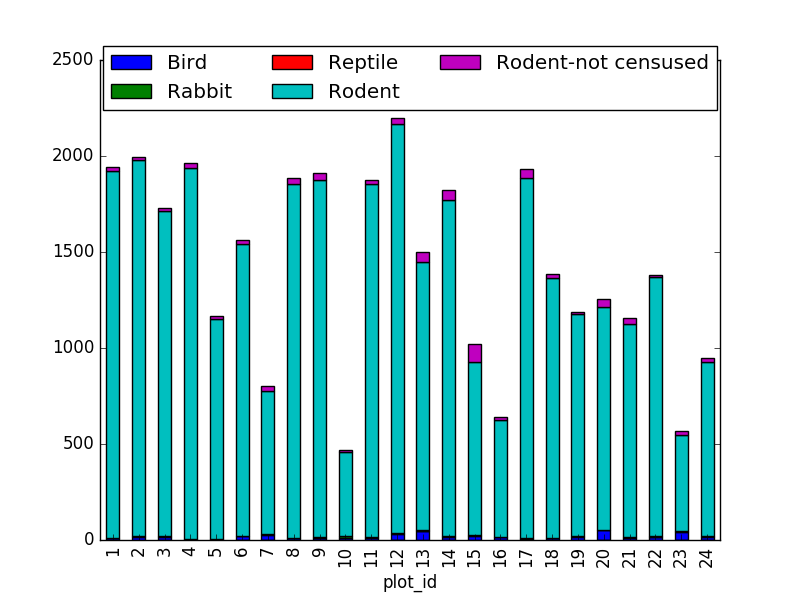
2. taxa por sexo por parcela: Otorguemos los valores ‘M|F’ a los valores Nan (también podrían cambiarse a ‘x’):
Número de taxa por cada combinación de parcela/sexo:
PYTHON
ntaxa_sex_site= merged_left.groupby(["plot_id", "sex"])["taxa"].nunique().reset_index(level=1)
ntaxa_sex_site = ntaxa_sex_site.pivot_table(values="taxa", columns="sex", index=ntaxa_sex_site.index)
ntaxa_sex_site.plot(kind="bar", legend=False)
plt.legend(loc='upper center', ncol=3, bbox_to_anchor=(0.5, 1.08),
fontsize='small', frameon=False)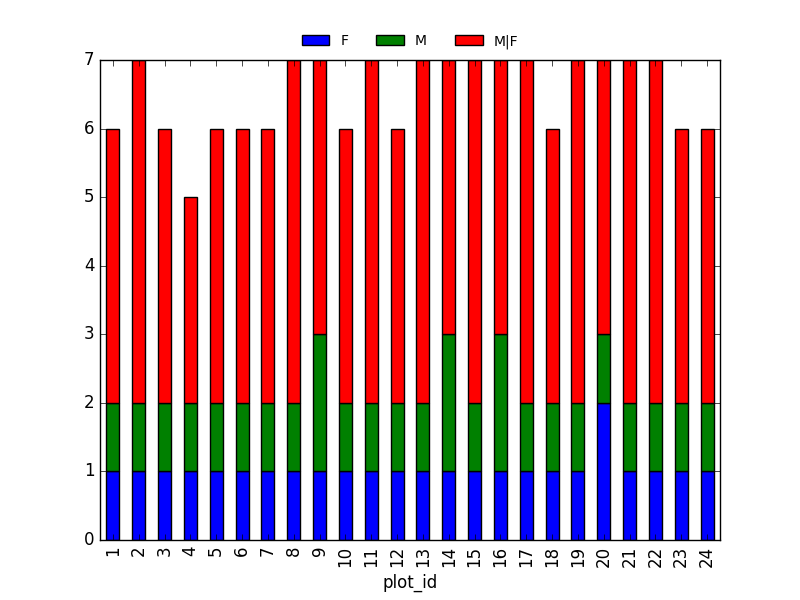
Sugerencia (sólo para discutir)):
También puede calcularse el número de individuos de cada taxa en cada parcela y por sexo:
PYTHON
sex_taxa_site = merged_left.groupby(["plot_id", "taxa", "sex"]).count()['record_id']
sex_taxa_site.unstack(level=[1, 2]).plot(kind='bar', logy=True)
plt.legend(loc='upper center', ncol=3, bbox_to_anchor=(0.5, 1.15),
fontsize='small', frameon=False)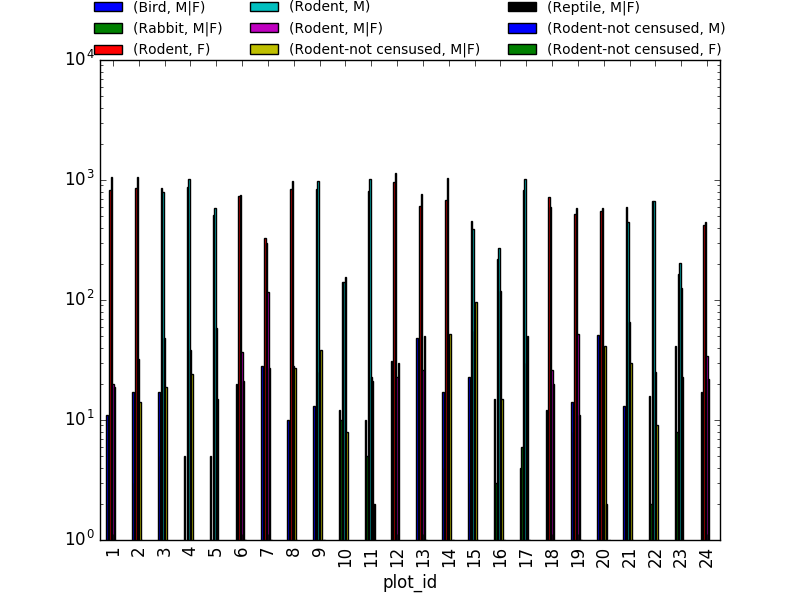
En verdad, éste gráfico no es el mejor que podría elegirse, pues no
es legible… Una primera alternativa para mejorarlo es utilizar
facets. Sin embargo, pandas/matplotlib no los provee
por defecto. Un ejemplo en matplotlib puro (usando M|F para
registros sin sexo definido):
PYTHON
fig, axs = plt.subplots(3, 1)
for sex, ax in zip(["M", "F", "M|F"], axs):
sex_taxa_site[sex_taxa_site["sex"] == sex].plot(kind='bar', ax=ax, legend=False)
ax.set_ylabel(sex)
if not ax.is_last_row():
ax.set_xticks([])
ax.set_xlabel("")
axs[0].legend(loc='upper center', ncol=5, bbox_to_anchor=(0.5, 1.3),
fontsize='small', frameon=False)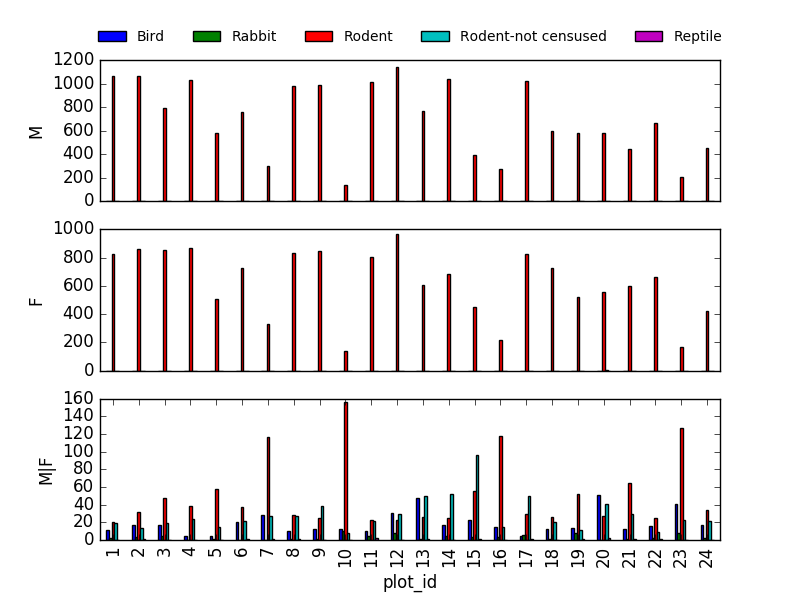
Sin embargo, sería mejor indicar Seaborn y Altair por sus tipos de visualizaciones multivariadas.
- En la carpeta de datos, hay un archivo
plots.csvque contiene información sobre el tipo asociado con cada parcela. Usa esos datos para resumir el número de parcelas por tipo de parcela.
- Calcula un índice de diversidad de su elección para control vs
parcelas de rodamiento de roedores. El índice debe considerar tanto la
abundancia de especies como el número de especies. Puedes optar por
utilizar el simple índice
de biodiversidad descrito aquí que calcula la biodiversidad como:
el número de especies en la parcela / el número total de individuos en la parcela = índice de biodiversidad.
PYTHON
merged_site_type = pd.merge(merged_left, plot_info, on='plot_id')
# para cada parcela, recupera el número de especies por parcela
nspecies_site = merged_site_type.groupby(["plot_id"])["species"].nunique().rename("nspecies")
# para cada parcela, recupera el número de individuos
nindividuals_site = merged_site_type.groupby(["plot_id"]).count()['record_id'].rename("nindiv")
# combina las dos series
diversity_index = pd.concat([nspecies_site, nindividuals_site], axis=1)
# calcula el índice de diversidad
diversity_index['diversity'] = diversity_index['nspecies']/diversity_index['nindiv']Generando un gráfico de barras:
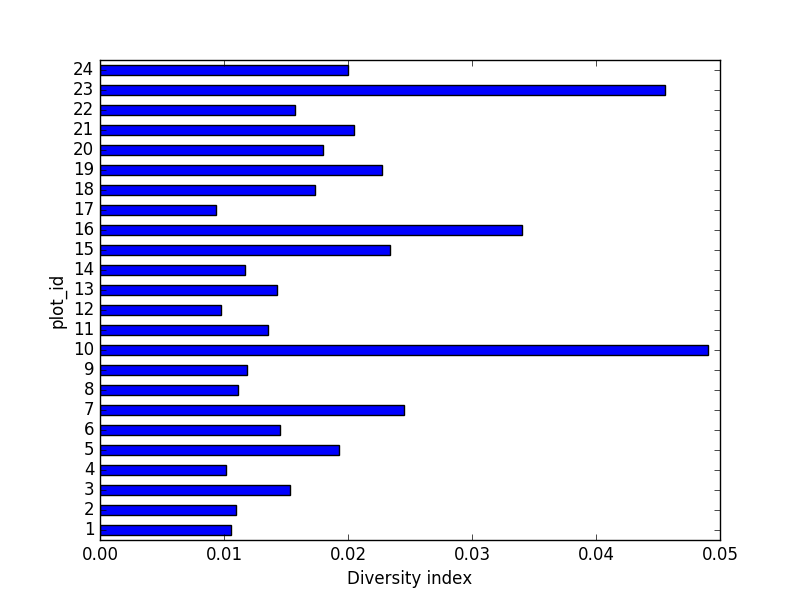
06-loops-and-functions
Desafíos sobre bucles básicos
-
¿Qué pasa si no incluimos la palabra clave
pass?SyntaxError: Reescribe el bucle de tal forma que los animales estén separados por comas y no por una línea nueva. (Pista: Puedes concatenar cadenas de caracteres usando el signo más. Por ejemplo,
print(string1 + string2)resulta en ‘string1string2’).
Este bucle también agrega una coma luego del último animal. Una
solución mejor, sin bucles, sería: ','.join(animals)
Desafíos sobre modificación de bucles
- Algunas de las encuestas que guardaste tienen datos faltantes
(tienen valores nulos que salen como
NaN- No es un número (en inglés) - en los DataFrames y no salen en los archivos de texto). Modifica el bucle for para que las entradas que tengan valores nulos no sean incluidas en los archivos anuales.
- Supongamos que solo quieres revisar los datos cada cierto múltiplo de años. ¿Cómo modificarías el bucle para generar un archivo de datos cada cinco años comenzando desde 1977?
Aunque podrías hacer la lista manualmente, ¿por qué no recuperas el primer y el último año a partir del código?
PYTHON
n_year = 5 # mejor visión general si defines una variable
first_year = surveys_df['year'].min()
last_year = surveys_df['year'].max()
for year in range(first_year, last_year, n_year):
print(year)
# Selecciona los datos para los años correctos
surveys_year = surveys_df[surveys_df.year == year].dropna()- En vez de separar la información por años, un colega tuyo quiere hacer el análisis separando por especies. ¿Cómo escribirías un único archivo CSV por cada especie?
De forma similar al ejemplo anterior, pero usando la columna
species_id: surveys_df['species_id'].unique().
Sin embargo, usar los nombres de especies mejoraría la interpretación de
los nombres de archivos. Un join con las especies:
merged_left = pd.merge(left=surveys,right=species, how='left', on="species_id")
y usando la columna species.
Desafíos sobre funciones
- Cambia los valores de los argumentos en la función y mira su salida.
- Intenta llamar a la función usando la cantidad equivocada de
argumentos (es decir, diferente de 2) o sin asignar la llamada de la
función a una variable (sin poner
product_of_inputs =). - Declara una variable dentro de una función y prueba a encontrar en dónde existe (Pista: ¿puedes imprimirla desde fuera de la función?)
- Explora qué sucede cuando una variable tiene el mismo nombre adentro y afuera de la función. ¿Qué le ocurre a la variable global cuando cambias el valor de la variable local?
Para mayor claridad, ¡demuéstralo en un entorno de debugging!
Desafíos adicionales sobre funciones
- Añade dos argumentos a las funciones que escribimos que tomen el path del directorio donde los archivos serán escritos y el root del nombre del archivo. Crea un nuevo conjunto de archivos con un nombre diferente en un directorio diferente.
PYTHON
def one_year_csv_writer(this_year, all_data, folder_to_save, root_name):
"""
Escribe un archivo csv para los datos de un año dado.
Parámetros
---------
this_year : int
año para el cual se extraen datos
all_data: pd.DataFrame
DataFrame con datos de múltiples años
folder_to_save : str
carpeta para guardar los archivos de datos
root_name: str
raíz de los nombres de archivo donde se guardan los datos
"""
# Selecciona datos para el año
surveys_year = all_data[all_data.year == this_year]
# Escribe el nuevo DataFrame a un archivo csv
filename = os.path.join(folder_to_save, ''.join([root_name, str(this_year), '.csv']))
surveys_year.to_csv(filename)También adapta la función yearly_data_csv_writer con los
inputs adicionales.
- ¿Cómo podrías usar la función
yearly_data_csv_writerpara crear un archivo CSV para solo un año? (Pista: piensa sobre la sintaxis pararange)
Adapta los argumentos de entrada, por ejemplo: 1978, 1979.
Desafíos sobre manejo de output
- Haz que las funciones retornen una lista de los archivos que
escribieron. Hay muchas formas en las que puedes hacer esto (¡y deberías
intentarlas todas!):
- cualquiera de las dos funciones podría imprimir algo en pantalla,
Sólo agrega el comando
print("year " + str(this_year)+ " written to disk") - cualquiera podría usar
returnpara retornar números o cadenas de caracteres cada vez que se llaman, - o podrías hacer una combinación de estas dos estrategias.
- Podrías también intentar usar la librería
ospara listar los contenidos de directorios.os.listdir
- cualquiera de las dos funciones podría imprimir algo en pantalla,
Sólo agrega el comando
Implementación dentro de la función:
PYTHON
filenames = []
for year in range(start_year, end_year+1):
filenames.append(one_year_csv_writer(year, all_data, folder_to_save, root_name))
return filenamesExplora qué sucede cuando las variables son declaradas dentro de cada una de las funciones versus en el cuerpo principal de tu código (lo que está sin indentar). ¿Cuál es el alcance de las variables (es decir, dónde son visibles)?, ¿qué ocurre si tienen el mismo nombre pero valores diferentes?
¿Qué tipo de objeto corresponde a una variable declarada como
None? (Pista: crea una variable con el valorNoney usa la funcióntype())
SALIDA
NoneTypeCompara el comportamiento de la función
yearly_data_arg_testcuando los argumentos tienenNonecomo valor por defecto y cuando no tienen valores por defecto.¿Qué ocurre si solo incluimos un valor para
start_yearal llamar a la función?, ¿puedes escribir una llamada a la función con solo un valor paraend_year? (Pista: piensa en cómo la función debe estar asignándole valores a cada uno de sus argumentos - ¡esto está relacionado con la necesidad de poner los argumentos que no tienen valores por defecto antes de los que sí tienen valores por defecto en la definición de la función!)
Desafíos sobre modificación de funciones
- Reescribe las funciones
one_year_csv_writeryyearly_data_csv_writerpara que tengan argumentos keyword con valores por defecto.
PYTHON
def one_year_csv_writer(this_year, all_data, folder_to_save='./', root_name='survey'):
"""
Escribe un archivo csv para los datos de un año dado.
Parámetros
---------
this_year : int
año para el cual se extraen datos
all_data: pd.DataFrame
DataFrame con datos de múltiples años
folder_to_save : str
carpeta para guardar los archivos de datos
root_name: str
raíz de los nombres de archivo donde se guardan los datos
"""
# Selecciona datos para el año
surveys_year = all_data[all_data.year == this_year]
# Escribe el nuevo DataFrame a un archivo csv
filename = os.path.join(folder_to_save, ''.join([root_name, str(this_year), '.csv']))
surveys_year.to_csv(filename)- Modifica las funciones de tal forma que no creen archivos para un
año si éste no está en los datos y que muestre una alerta al usuario
(Pista: usa condicionales para esto. Si quieres un reto más, ¡usa
try!)
PYTHON
# Escribe el nuevo DataFrame a un archivo csv
if len(surveys_year) > 0:
filename = os.path.join(folder_to_save, ''.join([root_name, str(this_year), '.csv']))
surveys_year.to_csv(filename)
else:
print("No data for year " + str(this_year))- El código que has escrito hasta este momento usando el bucle for está bastante bien, pero no necesariamente es reproducible con datasets diferentes. Por ejemplo, ¿qué pasa con el código si tenemos datos para más años? Usando las herramientas que aprendiste en las actividades anteriores, crea una lista de todos los años representados en los datos. Después crea un bucle para procesar tu información, comenzando desde el primer año y terminando en el último usando la lista.
PYTHON
def yearly_data_csv_writer(all_data, yearcolumn="year",
folder_to_save='./', root_name='survey'):
"""
Escribe archivos csv separados para los datos de cada año.
all_data --- DataFrame con datos de múltiples años
yearcolumn --- nombre de columna con el año de los datos
folder_to_save --- carpeta para guardar los archivos de datos
root_name --- inicio de los nombres de archivo almacenados
"""
years = all_data["year"].unique()
# "end_year" es el último año de los datos que queremos extraer, así que hacemos un bucle hasta end_year+1
filenames = []
for year in years:
filenames.append(one_year_csv_writer(year, all_data, folder_to_save, root_name))
return filenames07-visualization-ggplot-python
Si las estudiantes tienen problemas para generar el output, u ocurre algo con éste, existe un archivo llamado “sample output” con los datos que ellas debían generar en la lección 03.
Las notebooks de iPython para graficar pueden verse
en la carpeta _extras
08-putting-it-all-together
Las científicas suelen operar sobre ecuaciones matemáticas. La
capacidad para usar estas ecuaciones en sus gráficas otorga mucho valor
agregado. Por fortuna, Matplotlib provee herramientas poderosas para el
control de texto. Una de ellas es la capacidad para usar la notación
matemática de LaTeX al usar texto (puedes aprender más sobre la notación
matemática de LaTeX aquí: https://en.wikibooks.org/wiki/LaTeX/Mathematics).
Para usar notación matemática, enciera tu texto con el signo
$. LaTeX usa mucho el caracter de barra invertida o
backlash (“\”). Como este caracter tiene un significado
especial en las secuencias de caracteres de Python, deberían
reemplazarse todas las barras invertidas relacionadas con LaTeX por dos
barras invertidas.
PYTHON
plt.plot(t, t, 'r--', label='$y=x$')
plt.plot(t, t**2 , 'bs-', label='$y=x^2$')
plt.plot(t, (t - 5)**2 + 5 * t - 0.5, 'g^:', label='$y=(x - 5)^2 + 5 x - \\frac{1}{2}$') # nota la barra invertida doble
plt.legend(loc='upper left', shadow=True, fontsize='x-large')
# Nota las dobles barras invertidas en la línea de abajo
plt.xlabel('Éste es el eje x. También puede contener matemática, como $\\bar{x}=\\frac{\\sum_{i=1}^{n} {x}} {N}$')
plt.ylabel('Éste es el eje y')
plt.title('Éste es el título de la figura')
plt.show()