Combinando DataFrames con Pandas
Última actualización: 2023-02-07 | Mejora esta página
En muchas situations del “mundo real”, los datos que queremos usar
proceden de múltiples archivos. Frecuentemente necesitamos combinar
estos archivos en un uniquo DataFrame para analizar los
datos. El paquete pandas proporciona varios
métodos de combinar DataFrames incluyendo
merge y concat.
Hoja de ruta
Preguntas
- ¿Puedo trabajar con datos de diferentes fuentes?
- ¿Cómo puedo combinar datos de diferentes datasets?
Objetivos
- Combinar datos de varios diferentes archivos en un único DataFrame
usando
mergeyconcat. - Combinar dos DataFrames usando un ID único encontrado en ambos DataFrames.
- Unir DataFrames usando campos comunes (unión por claves).
Para trabajar en los ejemplos abajo, necesitamos primero cargar los archivos de species y surveys dentro de pandas DataFrames. En Python:
PYTHON
import pandas as pd
surveys_df = pd.read_csv("data/surveys.csv",
keep_default_na=False, na_values=[""])
surveys_df
record_id month day year plot species sex hindfoot_length weight
0 1 7 16 1977 2 NA M 32 NaN
1 2 7 16 1977 3 NA M 33 NaN
2 3 7 16 1977 2 DM F 37 NaN
3 4 7 16 1977 7 DM M 36 NaN
4 5 7 16 1977 3 DM M 35 NaN
... ... ... ... ... ... ... ... ... ...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[35549 rows x 9 columns]
species_df = pd.read_csv("data/species.csv",
keep_default_na=False, na_values=[""])
species_df
species_id genus species taxa
0 AB Amphispiza bilineata Bird
1 AH Ammospermophilus harrisi Rodent
2 AS Ammodramus savannarum Bird
3 BA Baiomys taylori Rodent
4 CB Campylorhynchus brunneicapillus Bird
.. ... ... ... ...
49 UP Pipilo sp. Bird
50 UR Rodent sp. Rodent
51 US Sparrow sp. Bird
52 ZL Zonotrichia leucophrys Bird
53 ZM Zenaida macroura Bird
[54 rows x 4 columns]Ten en cuenta que el método read_csv que usamos puede
tomar opciones adicionales que no hemos usado anteriormente. Muchas
funciones en Python tienen un conjunto de opciones que
se pueden ser definidas por el usuario si es necesario. En este caso,
hemos indicado a pandas que asigne valores vacíos en
nuestro CSV como NaN
keep_default_na=False, na_values=[""]. Explora
sobre todas las optciones de read_csv a través de este
enlace.
Concatenando DataFrames
Podemos usar la función concat en pandas para agregar
columnas o filas de un DataFrame a otro. Tomemos dos
subconjuntos de nuestros datos para ver cómo esto trabaja.
PYTHON
# Lee las primeras 10 líneas de la tabla de encuestas.
survey_sub = surveys_df.head(10)
# Agarra las últimas 10 filas
survey_sub_last10 = surveys_df.tail(10)
# Restablecer los valores de índice a la segunda __DataFrame__ adjunta correctamente
survey_sub_last10=survey_sub_last10.reset_index(drop=True)
# drop=True opción evita agregar una nueva columna de índice con valores de índice antiguosCuando concatenamos DataFrames, necesitamos
especificar el eje. axis=0 dice pandas para apilar el
segundo DataFrame debajo del primero. Será
automáticamente detecta si los nombres de las columnas son iguales y se
apilarán en consecuencia. axis=1 apilará las columnas en el
segundo DataFrame a la DERECHA del primer
DataFrame. Para apilar los datos verticalmente,
necesitamos asegurarnos de que tenemos las mismas columnas y el formato
de columna asociado en los dos datasets. Cuando apilamos
horizontalmente, queremos asegurarnos de que lo que estamos haciendo
tiene sentido (es decir, los datos son relacionados de alguna
manera).
PYTHON
# Apilar los __DataFrames__ uno encima del otro
vertical_stack = pd.concat([survey_sub, survey_sub_last10], axis=0)
# Coloque los __DataFrames__ de lado a lado
horizontal_stack = pd.concat([survey_sub, survey_sub_last10], axis=1)Valores de índice de fila y Concat
¿Dale una ojeada al vertical_stack
DataFrame? ¿Notaste algo inusual? Los índices de fila
para los dos data frames survey_sub
ysurvey_sub_last10 se han repetido. Podemos reindexar el
nuevo data frame usando el método reset_index().
Escribiendo datos a CSV
Podemos usar el comando to_csv para exportar un
DataFrame en formato CSV. Nota que el código a
continuación guardará los datos por defecto en el directorio de trabajo
corriente. Podemos guárdelo en un directorio diferente agregando el
nombre de la carpeta y una barra al archivo
vertical_stack.to_csv ('foldername/out.csv'). Usamos el
‘índice = Falso’ para que pandas no incluye el número de índice para
cada línea.
Revise su directorio de trabajo para asegurarse de que el CSV se haya escrito correctamente, y que puedas abrirlo! Si quieres, intenta subirlo de vuelta a Python para asegurarte se importa correctamente.
PYTHON
# Para los memes lee nuestro archivo en Python y asegúrese de que todo se vea bien.
new_output = pd.read_csv('data_output/out.csv', keep_default_na=False, na_values=[""])Challenge - Combine Data
En la carpeta de datos, hay dos archivos de datos de encuestas:
survey2001.csv y survey2002.csv. Lee los datos
en Python y combina los archivos para hacer un
DataFrame nuevo. Crea una gráfica del peso promedio de
la parcela, plot_id, por año agrupada por sexo. Exporta tus
resultados como CSV y asegúrate de que se lean correctamente en
Python.
Unión de los DataFrames
Cuando concatenamos nuestros DataFrames, simplemente los agregamos unos a otros - apilándolos verticalmente o lado a lado. Otra forma de combinar DataFrames es usar columnas en cada dataset que contienen valores comunes (un ID única común). Combinando DataFrames utilizando un campo común se llama “joining” (unión). Las columnas que contienen los valores comunes se llaman “join key(s)” (claves de unión). Muchas veces uniendo DataFrames de esta manera es útil cuando un DataFrame es una “lookup table” (tabla de búsqueda) que contiene datos adicionales que queremos incluir en el otro DataFrame.
NOTA: Este proceso de unir tablas es similar a lo que hacemos con las tablas en una base de datos SQL.
Por ejemplo, el archivo species.csv con el que hemos
estado trabajando es una tabla de búsqueda. Esta tabla contiene el
código de género, especie y taxa para 55 especies. El código de la
especie es único para cada línea. Estas especies se identifican en los
datos de nuestra encuesta y también utilizan el código único de
especies. En lugar de agregar 3 columnas más para el género, las
especies y los taxones a cada una de las 35,549 líneas de la tabla de
datos de la encuesta, podemos mantener la tabla más corta con la
información de la especie. Cuando queremos accesar esa información,
podemos crear una consulta que une las columnas adicionales de
información a los datos de la encuesta.
Almacenar los datos de esta manera tiene muchos beneficios, entre ellos:
Asegura la consistencia en la ortografía de los atributos de las especies (género, especie y taxones) dado que cada especie solo se ingresa una vez. ¡Imagine las posibilidades de errores de ortografía al ingresar el género y las especies miles de veces!
También nos facilita realizar cambios en la información de la especie una vez sin tener que encontrar cada instancia en los datos de la encuesta.
Optimiza el tamaño de nuestros datos.
Unión de Dos DataFrames
Para comprender mejor las uniones, tomemos las primeras 10 líneas de
nuestros datos como un subconjunto con para trabajar. Usaremos el método
.head para hacer esto. También vamos a importar un
subconjunto de la tabla de especies.
PYTHON
# Lee las primeras 10 líneas de la tabla de encuestas.
survey_sub = surveys_df.head(10)
# Importe un penqueño subconjunto de los datos de especies diseñados para esta parte de la lección.
# Esa archivado en la carpeta de datos.
species_sub = pd.read_csv('data/speciesSubset.csv', keep_default_na=False, na_values=[""])En este ejemplo, species_sub es la tabla de búsqueda que
contiene género, especie y nombres de taxa que queremos unir con los
datos en survey_sub para producir un nuevo
DataFrame que contiene todas las columnas de
species_df y survey_df.
Identifying join keys
Para identificar las claves de combinación adecuadas, primero necesitamos saber cuáles campos son compartidos entre los archivos (DataFrames). Podríamos inspeccionar los dos DataFrames para identificar estas columnas. Si tenemos suerte, los dos DataFrames tendrán columnas con el mismo nombre que también contienen los mismos datos. Si somos menos afortunados, necesitamos identificar una columna (con nombre diferente) en cada DataFrame que contiene la misma información.
PYTHON
>>> species_sub.columns
Index([u'species_id', u'genus', u'species', u'taxa'], dtype='object')
>>> survey_sub.columns
Index([u'record_id', u'month', u'day', u'year', u'plot_id', u'species_id',
u'sex', u'hindfoot_length', u'weight'], dtype='object')En nuestro ejemplo, la clave de unión es la columna que contiene el
identificador de especie de dos letras, que se llama
species_id.
Ahora que conocemos los campos con los atributos de ID de especies comunes en cada DataFrame, estamos casi listos para unir nuestros datos. Sin embargo, porque hay diferentes tipos de uniones, también debemos decidir qué tipo de unión tiene sentido para nuestro análisis.
Uniones internas
El tipo más común de unión se llama inner join (unión interna). Una combinación interna combina dos DataFrames basados en una clave de unión y devuelve un nuevo DataFrame que contiene solo aquellas filas que tienen valores coincidentes entre los dos DataFrames originales.
Las uniones internas producen un DataFrame que contiene solo filas donde el valor que es el subjecto de la unión existe en las dos tablas. Un ejemplo de una unión interna, adaptado de esta página se encuentra a continuación:
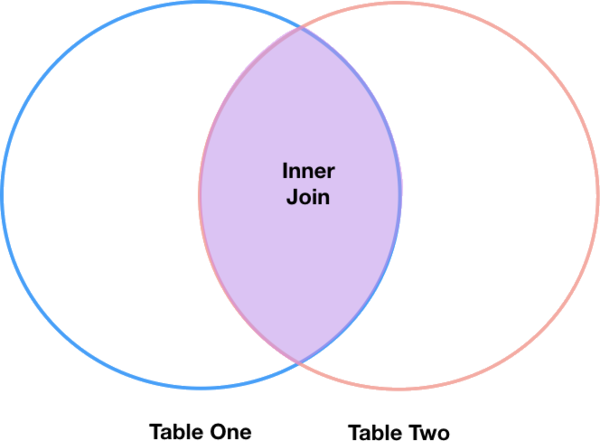
La función en pandas para realizar uniones se llama
merge y una unión interna es la opción por defecto:
PYTHON
merged_inner = pd.merge(left=survey_sub,right=species_sub, left_on='species_id', right_on='species_id')
# En este caso, `species_id` es el único nombre de columna en los dos __DataFrames__, entonces si omitimos
# los argumentos `left_on` y `right_on` todavía obtendríamos el mismo resultado
# ¿Cuál es el tamaño de los datos en el resultado?
merged_inner.shape
merged_innerOUTPUT:
SALIDA
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 8 7 16 1977 1 DM M 37
6 9 7 16 1977 1 DM F 34
7 7 7 16 1977 2 PE F NaN
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN Dipodomys merriami Rodent
6 NaN Dipodomys merriami Rodent
7 NaN Peromyscus eremicus RodentEl resultado de una unión interna de survey_sub y
species_sub es un nuevo DataFrame que
contiene el conjunto combinado de columnas de survey_sub y
species_sub. Solo contiene filas que tienen
códigos de dos letras de especies que son iguales en el
survey_sub y el species_sub
DataFrames. En otras palabras, si una fila en
survey_sub tiene un valor de species_id que
no aparece en la species_id columna de
species, no será incluirá en el DataFrame
devuelto por una unión interna. Del mismo modo, si una fila en
species_sub tiene un valor de species_id que
no aparece en la columna species_id de
survey_sub, esa fila no será incluida en el
DataFrame devuelto por una unión interna.
Los dos DataFrames a los que queremos unir se pasan
a la función merge usando el argumento de left
y right. El argumento left_on = 'species' le
dice a merge que use la columna species_id
como la clave de unión de survey_sub (el left
DataFrame). De manera similar, el argumento
right_on = 'species_id' le dice a merge que
use la columna species_id como la clave de unión
despecies_sub (el right
DataFrame). Para uniones internas, el orden de los
argumentos left yright no importa.
El resultado merged_inner DataFrame
contiene todas las columnas desurvey_sub (ID de registro,
mes, día, etc.), así como todas las columnas de species_sub
(especies_id, género, especie y taxa).
Date cuenta que merged_inner tiene menos filas que
survey_sub. Esto es una indicación de que había filas en
survey_df con valor(es) para species_id que no
existen como valor(es) para species_id en
species_df.
Unión izquierda
¿Qué pasa si queremos agregar información de species_sub
a survey_sub sin perdiendo información de
survey_sub? En este caso, utilizamos un diferente tipo de
unión llamada “left outer join (unión externa
izquierda)”, or a “left join (unión izquierda)”.
Como una combinación interna, una unión izquierda utiliza las claves
de unión para combinar dos DataFrames. Diferente a una
unión interna, una unión izquierda devolverá todas las filas
del left DataFrame, hasta aquellas filas
cuyas claves de unión no tienen valores en el right
DataFrame. Filas en el left
DataFrame que faltan valores para las clave(s) de unión
en el right DataFrame simplemente tendrán
valores nulos (es decir, NaN o Ninguno) para las columnas en el
resultante DataFrame unido.
Nota: una unión izquierda todavía descartará las filas del
right DataFrame que no tienen valores para
la(s) clave(s) de unión en el left
DataFrame.

Una unión izquierda se realiza en pandas llamando a la misma función
merge utilizada para unión interna, pero usando el
argumento how = 'left':
PYTHON
merged_left = pd.merge(left=survey_sub,right=species_sub, how='left', left_on='species_id', right_on='species_id')
merged_left
**OUTPUT:**
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 6 7 16 1977 1 PF M 14
6 7 7 16 1977 2 PE F NaN
7 8 7 16 1977 1 DM M 37
8 9 7 16 1977 1 DM F 34
9 10 7 16 1977 6 PF F 20
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN NaN NaN NaN
6 NaN Peromyscus eremicus Rodent
7 NaN Dipodomys merriami Rodent
8 NaN Dipodomys merriami Rodent
9 NaN NaN NaN NaNEl resultado DataFrame de una unión izquierda
(merged_left) se parece mucho al resultado
DataFrame de una unión interna
(merged_inner) en términos de las columnas que contiene.
Sin embargo, a diferencia de merged_inner,
merged_left contiene el mismo número de
filas como el DataFrame original
survey_sub. Cuando inspeccionamos merged_left,
encontramos que hay filas donde la información debería haber venido de
species_sub (es decir,species_id,
genus ytaxa) hace falta (contienen valores de
NaN):
PYTHON
merged_left[ pd.isnull(merged_left.genus) ]
**OUTPUT:**
record_id month day year plot_id species_id sex hindfoot_length \
5 6 7 16 1977 1 PF M 14
9 10 7 16 1977 6 PF F 20
weight genus species taxa
5 NaN NaN NaN NaN
9 NaN NaN NaN NaNEstas filas son aquellas en las que el valor de
species_id desurvey_sub (en este caso,
PF) no ocurre enspecies_sub.
Otros tipos de unión
La función merge de pandas admite otros dos tipos de
unión:
-
Right (outer) join unión derecha (exterior): se
invoca al pasar
how = 'right'como argumento. Similar a una unión izquierda, excepto que se guardan todas las filas delrightDataFrame, mientras que las filas delleftDataFrame sin coincidir con los valores de las claves de unión son descartadas. -
Full (outer) join unión completa (externa): se
invoca al pasar
how = 'outer'como argumento. Este tipo de unión devuelve todas las combinaciones de filas de los dos DataFrames; es decir., el DataFrame resultante estaráNaNdonde faltan datos en uno de los DataFrames. Este tipo de unión es muy raramente utilizado.
Desafíos Finales
Desafío - Distribuciones
Cree un nuevo DataFrame uniendo los contenidos de
survey.csv y Tablas species.csv. Luego calcula
y crea un gráfico de la distribución de:
- taxa por parcela
- taxa por sexo por parcela
Desafío - Índice de Diversidad
- En la carpeta de datos, hay un gráfico
CSVque contiene información sobre el tipo asociado con cada parcela. Usa esos datos para resumir el número de parcelas por tipo de parcela. - Calcula un índice de diversidad de su elección para control vs parcelas de rodamiento de roedores El índice debe considerar tanto la abundancia de especies como el número de especies. Puedes optar por utilizar el simple índice de biodiversidad descrito aquí que calcula la diversidad como:
el número de especies en la parcela / el número total de individuos en la parcela = índice de biodiversidad.
Puntos Clave
- Podemos usar la función
concaten pandas para agregar columnas o filas de un DataFrame a otro. - Se pueden combinar DataFrames en base a columnas en cada dataset que contienen valores comunes (un ID única común), esta combinación utilizando un campo común se llama “joining” (unión).
- Es posible realizar distintos tipos de uniones: interna cuyo resultado solamente tiene las filas donde coinciden las columnas clave en ambos DataFrame, externa hacia la izquierda o la derecha, si queremos conservar las filas del DataFrame de origen o destino respectivamente, o una unión externa completa, con filas para todas las combinaciones de las columnas clave.