Indexación, segmentación y creación de subconjuntos a partir de DataFrames en Python
Última actualización: 2023-02-07 | Mejora esta página
En la lección 01, leímos un archivo CSV y cargamos los datos en un pandas DataFrame. Aprendimos:
Hoja de ruta
Preguntas
- ¿Cómo puedo acceder a un dato específico en mi ‘dataset’?
- ¿Cómo pueden ayudarme Python y Pandas a analizar mis datos?
Objetivos
- Describir que es indexación en base-0.
- Manipular y extraer datos usando encabezados de columnas e índices.
- Usar ‘slicing’ para seleccionar conjuntos de datos de un ‘DataFrame’.
- Emplear etiquetas e índices enteros para seleccionar rangos de datos en un ‘DataFrame’.
- Reasignar valores dentro de subconjuntos de datos de un ‘DataFrame’.
- Crear una copia de un ‘DataFrame’.
- Consultar/Seleccionar un subconjunto de datos usando un conjunto de criterios utilizando los siguientes operadores: =, !=, >, <, >=, <=.
- Localizar subconjuntos de datos utilizando máscaras.
- Describir objetos tipo ‘boolean’ en Python y manipular datos usando ‘booleans’.
- como guardar el DataFrame en un objeto,
- como realizar operaciones matemáticas básica sobre datos,
- como calcular resúmenes estadísticos, y
- como crear gráficos a partir de los datos.
En esta lección, exploraremos formas de acceder a diferentes partes de los datos usando:
- indexación,
- segmentación, y
- creación de subconjuntos.
Cargando nuestros datos
Vamos a continuar usando el dataset surveys que usamos con la lección anterior. Reabrámoslo y leamos los datos de nuevo:
Indexando y Fragmentando en Python
A menudo necesitamos trabajar con subconjuntos de un objeto DataFrame. Existen diferentes maneras de lograr esto, incluyendo: usando etiquetas (encabezados de columnas), rangos numéricos, o índices de localizaciones específicas x,y.
Seleccionando datos mediante el uso de Etiquetas (Encabezados de Columnas)
Utilizamos corchetes [] para seleccionar un subconjunto
de un objeto en Python. Por ejemplo, podemos seleccionar todos los datos
de una columna llamada species_id del
surveys_df DataFrame usando el nombre de
la columna. Existen dos maneras de hacer esto:
PYTHON
# Sugerencia: usa el método .head() que vimos anteriormente para hacer la salida más corta
# Método 1: selecciona un 'subconjunto' de los datos usando el nombre de la columna
surveys_df['species_id']
# Método 2: usa el nombre de la columna como un 'atributo'; esto produce la misma salida
surveys_df.species_idTambién podemos crear un nuevo objeto que contiene solamente los
datos de la columna species_id de la siguiente manera:
PYTHON
# Crea un objeto, `surveys_species`, que solamente contenga la columna `species_id`
surveys_species = surveys_df['species_id']También podemos pasar una lista de nombres de columnas, a manera de índice para seleccionar las columnas en ese orden. Esto es útil cuando necesitamos reorganizar nuestros datos.
NOTA: Si el nombre de una columna no esta incluido
en el DataFrame, se producirá una excepción (error).
PYTHON
# Selecciona las especies y crea un gráfico con las columnas del **DataFrame**
surveys_df[['species_id', 'plot_id']]
# ¿Qué pasa cuando invertimos el orden?
surveys_df[['plot_id', 'species_id']]
# ¿Qué pasa si preguntamos por una columna que no existe?
surveys_df['speciess']Python nos informa que tipo de error es en el rastreo, en la parte
inferior dice KeyError: 'speciess' lo que significa que
speciess no es un nombre de columna (o Key
que está relacionado con el diccionario de tipo de datos de Python).
Extrayendo subconjuntos basados en rangos: Segmentando
RECORDATORIO: Python usa Indexación en base-0
Recordemos que Python usa indexación en base-0. Esto quiere decir que el primer elemento en un objeto esta localizado en la posición 0. Esto es diferente de otros lenguajes como R y Matlab que indexan elementos dentro de objetos iniciando en 1.
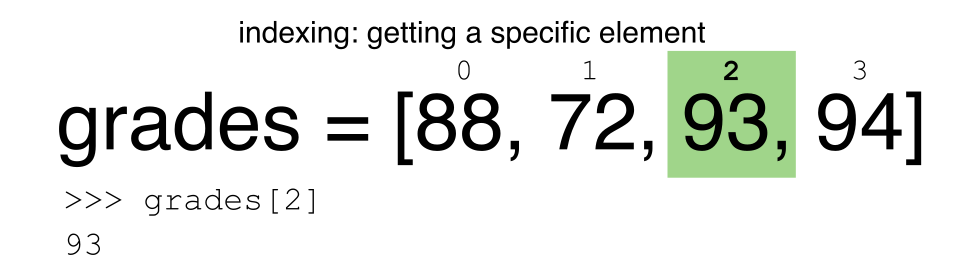
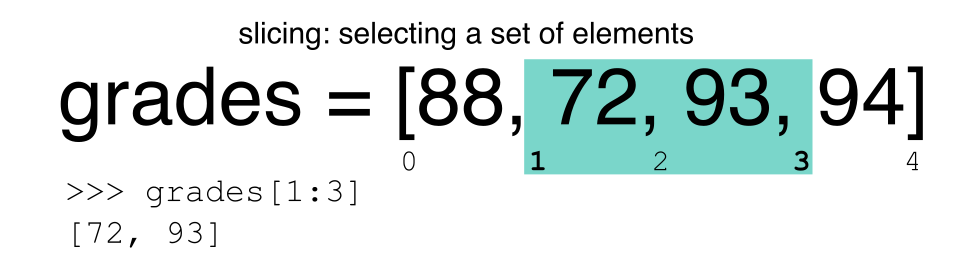
Segmentando Subconjuntos de Filas en Python
La segmentación utilizando el operador [] selecciona un
conjunto de filas y/o columnas de un DataFrame. Para
segmentar un conjunto de filas, usa la siguiente sintaxis:
data[start:stop]. Cuando se hace segmentación en pandas, el
límite inicial (start) se incluye en los datos de
salida. El límite final (stop) es un paso MÁS ALLÁ de
la fila que desea seleccionar. Así que si deseas seleccionar las filas
0, 1 y 2, tu código se vería así:
El límite final en Python es diferente del que puedes estar acostumbrado a usar en Lenguajes como Matlab y R.
PYTHON
# Selecciona las primeras cinco filas (con índices 0, 1, 2, 3, 4)
surveys_df[:5]
# Selecciona el último elemento de la lista
# (el segmento comienza en el último elemento y finaliza al final de la lista)
surveys_df[-1:]También podemos reasignar valores dentro de subconjuntos de nuestro DataFrame.
Pero antes de hacerlo, veamos la diferencia entre el concepto de copiar objetos y el concepto de referenciar objetos en Python.
Copiar Objetos vs Referenciar Objetos en Python
Empecemos con un ejemplo:
PYTHON
# Usando el método 'copy()'
true_copy_surveys_df = surveys_df.copy()
# Usando el operador '='
ref_surveys_df = surveys_dfPuedes pensar que el código ref_surveys_df = surveys_df
crea una copia nueva y distinta de objeto DataFrame
surveys_df. Sin embargo, usar el operador = en
una instrucción simple de la forma y = x
no crea una copia de nuestro
DataFrame. En lugar de esto, y = x crea
una variable nueva y que hace referencia al
mismo objeto al que x hace referencia.
Para decirlo de otra manera, solamente hay un objeto
(el DataFrame), y ambos objetos x y
y hacen referencia a él.
En contraste, el método copy() de un
DataFrame crea una copia verdadera del
DataFrame.
Veamos lo que sucede cuando reasignamos los valores dentro de un subconjunto del DataFrame que hace referencia a otro objeto DataFrame:
PYTHON
# Asigna el valor `0` a las primeras tres filas de datos en el **DataFrame**
ref_surveys_df[0:3] = 0Probemos el siguiente código:
PYTHON
# ref_surveys_df fue creado usando el operador '='
ref_surveys_df.head()
# surveys_df es el **DataFrame** original
surveys_df.head()¿Cuál es la diferencia entre estos dos DataFrames?
Cuando asignamos a las tres primeras filas el valor de 0
usando el DataFrame ref_surveys_df, el
DataFrame surveys_df también es
modificado. Recuerda que creamos el objeto ref_survey_df
arriba usando la instrucción ref_survey_df = surveys_df.
Por lo tanto surveys_df y ref_surveys_df hacen
referencia exactamente al mismo objeto DataFrame. Si
cualquiera de los dos objetos (ref_survey_df,
surveys_df) es modificado, el otro objeto va a observar los
mismos cambios.
Revisar y Recapitular:
-
Para crear una copia de un objeto, usamos el método copy() de un
DataFrame -
Para crear una referencia a un objeto usamos el operador
=
Muy bien, hora de practicar. Vamos a crear un nuevo objeto
DataFrame a partir del archivo CSV con los datos
originales.
Segmentando subconjuntos de filas y columnas en Python
Podemos seleccionar subconjuntos de datos, contenidos en rangos específicos de filas y columnas, usando etiquetas o indexación basada en números enteros.
-
loces usado principalmente para indexación basada en etiquetas. Permite usar números enteros pero son interpretados como una etiqueta. -
iloces usado para indexación basada en números enteros
Para seleccionar un subconjunto de filas y columnas
de nuestro objeto DataFrame, podemos usar el método
iloc. Por ejemplo, podemos seleccionar month,
day y year (que corresponden a las columnas 2,
3 y 4, si empezamos a contar las columnas en 1) para las primeras tres
filas, de la siguiente manera:
lo cual nos produce la siguiente salida
SALIDA
month day year
0 7 16 1977
1 7 16 1977
2 7 16 1977Ten en cuenta que pedimos un segmento de 0:3. Esto produjo 3 filas de datos. Cuando pides un segmento de 0:3, le estas diciendo a Python que comience en el índice 0 y seleccione las filas 0, 1, 2, hasta 3 pero sin incluir esta última.
Exploremos otras maneras de indexar y seleccionar subconjuntos de datos:
PYTHON
# Selecciona todas las columnas para las filas con índices entre 0 y 10
surveys_df.loc[[0, 10], :]
# ¿Qué salida produce el la siguiente instrucción?
surveys_df.loc[0, ['species_id', 'plot_id', 'weight']]
# ¿Qué pasa cuando ejecutas el siguiente código?
surveys_df.loc[[0, 10, 35549], :]NOTA: Las etiquetas utilizadas deben estar incluidas
en el DataFrame o se obtendrá un error de tipo
KeyError.
La indexación por etiquetas (loc) difiere de la
indexación por números enteros (iloc). Cuando usamos
loc, los limites inicial y final se
incluyen. Cuando usamos loc,
podemos usar números enteros, pero dichos números enteros harán
referencia a etiquetas usadas a manera de índice y no a la posición. Por
ejemplo, si usamos loc y seleccionamos 1:4 vamos a obtener
resultados diferentes que si usamos iloc para seleccionar
las filas 1:4.
Podemos seleccionar un dato específico utilizando la la intersección
de una fila y una columna dentro del DataFrame, junto con
la indexación basada en números enteros iloc:
PYTHON
# Sintaxis para encontrar un dato especifico dentro de un `DataFrame` utilizando indexación `iloc`
dat.iloc[fila, columna]En este ejemplo de iloc,
la salida es la siguiente
SALIDA
'F'Recuerda que la indexación en Python inicia en 0. Así que, la
direccíon basada en índice [2, 6] selecciona el elemento ubicado en la
intersección de la tercera fila (índice 2) y la séptima columna (índice
6) en el DataFrame.
Desafío - Rangos
- ¿Qué ocurre al ejecutar el siguiente código?:
surveys_df[0:1]surveys_df[:4]surveys_df[:-1]
- ¿Qué pasa al ejecutar este otro?:
dat.iloc[0:4, 1:4]dat.loc[0:4, 1:4]¿Qué diferencia observas entre los resultados de los comandos inmediatamente anteriores?
Creando subconjuntos de datos mediante el filtrado por criterios
También podemos seleccionar un subconjunto de nuestros datos,
mediante el filtrado de la data original, usando algún criterio. Por
ejemplo, podemos seleccionar todas las filas que tienen el valor de 2002
en la columna year:
Lo cual produce la siguiente salida:
PYTHON
record_id month day year plot_id species_id sex hindfoot_length weight
33320 33321 1 12 2002 1 DM M 38 44
33321 33322 1 12 2002 1 DO M 37 58
33322 33323 1 12 2002 1 PB M 28 45
33323 33324 1 12 2002 1 AB NaN NaN NaN
33324 33325 1 12 2002 1 DO M 35 29
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[2229 rows x 9 columns]También podemos seleccionar todas las filas que no contienen el año 2002:
También podemos definir conjuntos de criterios:
Hoja de referencia para sintaxis de Python
Podemos utilizar la sintaxis incluida a continuación, cuando queramos
hace consultas de datos por criterios en un DataFrame.
Experimenta seleccionando varios subconjuntos de los datos contenidos en
surveys_df.
- Igual a:
== - No igual o diferente de:
!= - Mayor que, menor que:
>or< - Mayor o igual que
>= - Menor o igual que
<=
Desafío - Consultas
Selecciona un subconjunto de filas, en el
DataFramesurveys_df, que contenga datos desde el año 1999 y que contenga valores enweightmenores o iguales a 8. ¿Cuántas filas obtuviste como resultado? ¿Cuántas filas obtuvo tu compañera?Puedes usar la función
isinde Python para hacer una consulta a unDataFrame, basada en una lista de valores según se muestra a continuación:
Usa la función isin para encontrar todos los
plots que contienen una especie en particular en el
DataFrame surveys_df. ¿Cuántos registros
contienen esos valores?
Experimenta con otras consultas. Crea una consulta que encuentre todas las filas con el valor de
weightmayor o igual a 0.El símbolo
~puede ser usado en Python para obtener lo opuesto a los datos seleccionados que hayas especificado. Es equivalente a no esta en. Escribe una consulta que seleccione todas las filas consexdiferente de ‘M’ o ‘F’ en los datos desurveys_df.
Usando máscaras para identificar una condición específica
Una máscara puede ser útil para identificar donde
existe o no exite un subconjunto específico de valores - por ejemplo,
NaN, o Not a Number en inglés. Para enternder el
concepto de máscaras, también tenemos que entender los objetos
BOOLEAN en Python.
Valores boleanos (boolean) incluyen
True o False. Por ejemplo,
PYTHON
# Asigna 5 a la variable x
x = 5
# ¿Qué nos devuelve la ejecución del siguiente código?
x > 5
# ¿Qué nos devuelve la ejecución de este?
x == 5Cuando le preguntamos a Python ¿Cuál es el valor de
x > 5?, obtenemos False. Esto se debe a que
la condición x es mayor que 5, no se cumple dado que
x es igual a 5.
Para crear una máscara booleana:
- Establece el criterio a ser evaluado como
TrueoFalse(ej.values > 5 = True) - Python evaluará cada valor en el objeto para determinar si el valor
cumple el criterio (
True) o no lo cumple (False). - Python crea un objeto de salida que es de la misma forma que el
objeto original, pero con un valor
TrueoFalsepor cada índice según corresponda.
Intentémoslo. Vamos a identificar todos los lugares en los datos de
survey que son null (que no existen o son
NaN). Podemos usar el método isnull para lograrlo. El
método isnull va a comparar cada celda con un valor
null. Si un elemento tiene un valor null, se
le asignará un nuevo valor de True en el objeto de
salida.
Un fragmento de la salida se muestra a continuación:
PYTHON
record_id month day year plot_id species_id sex hindfoot_length weight
0 False False False False False False False False True
1 False False False False False False False False True
2 False False False False False False False False True
3 False False False False False False False False True
4 False False False False False False False False True
[35549 rows x 9 columns]Para seleccionar las filas donde hay valores null,
podemos utilizar una máscara a manera de índice y obtener subconjuntos
de datos así:
PYTHON
# Para seleccionar solamente las filas con valores NaN, podemos utilizar el método 'any()'
surveys_df[pd.isnull(surveys_df).any(axis=1)]Nota que la columna weight de nuestro
DataFrame contiene varios valores null o
NaN. Exploraremos diferentes maneras de abordar esto en el
episodio de tipos
de datos y formatos.
También podemos utilizar isnull en una columna en
particular. ¿Qué salida produce el siguiente código?
PYTHON
# ¿Qué hace el siguiente código?
empty_weights = surveys_df[pd.isnull(surveys_df['weight'])]['weight']
print(empty_weights)Tomemos un minuto para observar las instrucciones de arriba. Estamos
usando el objeto booleano pd.isnull(surveys_df['weight']) a
manera de índice para surveys_df. Estamos pidiendo a Python
que seleccione aquellas filas que tienen un valor de NaN en
la columna weight.
Desafío - Revisando todo lo aprendido
Crea un nuevo objeto
DataFrameque solamente contenga observaciones cuyos valores en la columnasexno seanfemaleomale. Asigna cada valor desexen el nuevoDataFramea un nuevo valor de ‘x’. Determina el número total de valoresnullen el subconjunto.Crea un nuevo objeto
DataFrameque contenga solo observaciones cuyos valores en la columnasexseanmaleofemaley en los cuales el valor deweightsea mayor que 0. Luego, crea un gráfico de barra apiladas del promedio deweight, por parcela, con valoresmaleversusfemaleapilados por cada parcela.
Puntos Clave
- En Python, fragmentos de datos pueden ser accedidos usando índices, cortes, encabezados de columnas, y subconjuntos basados en condiciones.
- Python usa indexación base-0, en la cual el primer elemento de una lista, tupla o cualquier otra estructura de datos tiene un índice de 0.
- ‘Pandas’ permite usar procedimientos comunes de exploración de datos como indexación de datos, cortes y creación de subconjuntos basados en condiciones.