Comenzando con datos
Última actualización: 2023-02-07 | Mejora esta página
Trabajando con Pandas DataFrames en Python
Hoja de ruta
Preguntas
- ¿Cómo importar datos en Python?
- ¿Qué es Pandas?
- ¿Por qué debería de usar Pandas para trabajar con datos?
Objetivos
- Explorar el directorio del taller y descargar el dataset.
- Explicar qué es una biblioteca y para qué se usa.
- Describir qué es, Pandas, la Biblioteca de Análisis de Datos de Python.
- Cargar Pandas, la biblioteca de Análisis de Datos de Python.
- Usar
read_csvpara leer datos tabulares en Python. - Describir qué es un DataFrame en Python.
- Acceder y resumir datos guardados en un DataFrame.
- Definir la indexación y su relación con las estructuras de datos.
- Ejecutar operaciones matemáticas básicas y calcular estadísticas descriptivas sobre datos dentro de un Pandas Dataframe.
- Crear gráficos simples.
Podemos automatizar el proceso de manipular datos con Python. Vale la pena pasar tiempo escribiendo el código que haga estas tareas ya que una vez que se escribió, lo podemos usar una y otra vez en distintos conjuntos de datos que usen un formato similar. Esto hace a nuestros métodos fácilmente reproducibles. También resulta fácil compartir nuestro código con nuestros colegas y ellos pueden replicar el mismo análisis.
Comenzando en el mismo lugar
Para que la lección salga de la mejor manera posible, vamos a asegurarnos que todos estemos en el mismo directorio. Esto debería ayudarnos a evitar inconvenientes con los nombres de los directorios y los archivos. Navega al directorio del taller. Si tu estás trabajando en IPython Notebook asegurate de iniciar tu notebook en el directorio del taller.
Un comentario al margen es que hay bibliotecas de Python, como OS Library, las cuales pueden trabajar con la estructra de directorios, sin emebargo este no es nuestro objetivo el día de hoy.
Nuestros datos
Para esta lección, usaremos los datos de “Portal Teaching” que son subconjunto de los datos estudiados por Ernst et al. Long-term monitoring and experimental manipulation of a Chihuahuan Desert ecosystem near Portal, Arizona, USA.
Usaremos los datos de Portal
Project Teaching Database. Esta sección usa el archivo
surveys.csv el cual puede ser descargado desde: https://ndownloader.figshare.com/files/2292172
Vamos a estudiar la especie y el peso de los animales capturados en
sitios dentro de nuestra área de estudio. El conjunto de datos esta
guardado en un archivo .csv: cada línea tiene información
sobre un solo animal y las columnas representan:
| Columna | Descripción |
|---|---|
| record_id | identificador único de la observación |
| month | mes de observación |
| day | día de la observación |
| year | año de la observación |
| plot_id | ID de un sitio en particular |
| species_id | código de dos letras |
| sex | sexo del animal (“M”, “F”) |
| hindfoot_length | tamaño de pata en mm |
| weight | peso del animal en gramos |
Las primeras líneas de nuestro archivo se ven de la siguiente manera:
SALIDA
record_id,month,day,year,plot_id,species_id,sex,hindfoot_length,weight
1,7,16,1977,2,NL,M,32,
2,7,16,1977,3,NL,M,33,
3,7,16,1977,2,DM,F,37,
4,7,16,1977,7,DM,M,36,
5,7,16,1977,3,DM,M,35,
6,7,16,1977,1,PF,M,14,
7,7,16,1977,2,PE,F,,
8,7,16,1977,1,DM,M,37,
9,7,16,1977,1,DM,F,34,Acerca de las bibliotecas
Una biblioteca en Python contiene un conjunto de herramientas (llamadas funciones) que hacen tareas en nuestros datos. Importar una biblioteca es como traer un la pieza de laboratorio de nuestro locker y montarla en nuestra mesa de trabajo para usarla en nuestro proyecto. Una vez que la bilioteca está instalada, puede ser usada y llamada para hacer muchas tareas.
Pandas en Python
Una de las mejores opciones para trabajar con datos tabulares en Python es usar la Python Data Analysis Library (alias Pandas). La biblioteca Pandas provee estructuras de datos, genera gráficos de alta calidad con matplotlib y se integra de buena forma con otras bibliotecas que usan arrays de NumPy (la cual es otra biblioteca de Python).
Python no carga todas las bibliotecas disponibles por default. Se
tiene que usar el enunciado import en nuestro código para
usar las funciones de la biblioteca. Para importar una biblioteca se usa
la sintaxis import nombreDeLaBiblioteca. Si además le
queremos poner un sobrenombre para acortar los comandos, se puede
agregar as sobrenombreAUsar. Un ejemplo es importar la
biblioteca pandas usando su sobrenombre común pd como está
aquí abajo.
Cada vez que llamemos a una función que está en la biblioteca, se usa
la sintaxis NombreDeLaBiblioteca.NombreDeLaFuncion. Agregar
el nombre de la biblioteca con un . antes del nombre de la
función le indica a Python donde encontrar la función. En el ejemplo
anterior hemos importado a Pandas como pd. Esto significa
que no vamos a tener que escribir pandas cada vez que
llamemos a una función de Pandas y solo lo hagamos con su
sobrenombre.
Leyendo datos en CSV usando Pandas
Empezaremos encontrando y leyendo los datos del censo que están en
formato CSV. CSV son las siglas para Comma-Separated Values,
valores separados por coma, y es una manera común de guardar datos.
Otros símbolos pueden ser usados, te puedes encontrar valores separados
por tabuladores, por punto y coma o por espacios en blanco. Es fácil
remplazar un separador por otro, para usar tu aplicación. La primera
línea del archivo generalmente contiene los encabezados que dicen que
hay en cada columna. CSV (y otros separadores) hacen fácil compartir los
datos y pueden ser importados y exportados desde distintos programas,
incluyendo Microsoft Excel. Para más detalles sobre los archivos CSV, ve
la lección Organización
de datos en hojas de cálculo. Podemos usar la función de Pandas
read_csvpara abrir el archivo directamente en un DataFrame.
Entonces, ¿qué es un DataFrame?
Un DataFrame es una estructura de datos con dos
dimensiones en la cual se puede guardar datos de distintos tipos (como
caractéres, enteros, valores de punto flotante, factores y más) en
columnas. Es similar a una hoja de cálculo o una tabla de SQL o el
data.frame de R. Un DataFrame siempre
tiene un índice (con inicio en 0). El índice refiere a la posición de un
elemento en la estructura de datos.
PYTHON
# Observa que se usa pd.read_csv debido a que importamos a pandas como pd
pd.read_csv("data/surveys.csv")El comando anterior lleva a la siguiente salida:
SALIDA
record_id month day year plot_id species_id sex hindfoot_length weight
0 1 7 16 1977 2 NL M 32 NaN
1 2 7 16 1977 3 NL M 33 NaN
2 3 7 16 1977 2 DM F 37 NaN
3 4 7 16 1977 7 DM M 36 NaN
4 5 7 16 1977 3 DM M 35 NaN
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[35549 rows x 9 columns]Podemos ver que se leyeron 35,549 líneas. Cada una de los líneas
tiene 9 columnas. La primera columna es el índice del DataFrame. El
índice es usado para identificar la posición de los datos, pero no es
una columna del DataFrame. Parace ser que la función
read_csvde Pandas leyó el archivo correctamente. Sin
embargo, no hemos salvado ningún dato en memoria por lo que no podemos
trabajar con estos. Necesitamos asignar el DataFrame a
una variable. Recuerda que una variable es el nombre para un valor, como
xo data. Podemos crear un nuevo objeto con el
nombre de la variable y le asignamos un valor usando =.
Llamemos los datos del censo importados surveys_df:
Notemos que cuando asignamos los datos importado a un
DataFrame a una variable, Python no produce ninguna
salida a pantalla. Podemos ver el contenido de surveys_df
escribiendo el nombre en la línea de comando de Python.t.
el cual imprime los contenidos como anteriormente.
Nota: si la salida es más ancha que la pantalla de teminal al imprimirlo se verá algo distinto conforme el gran conjunto de datos pasa. Se podría ver simplemente la última columna de los datos:
SALIDA
17 NaN
18 NaN
19 NaN
20 NaN
21 NaN
22 NaN
23 NaN
24 NaN
25 NaN
26 NaN
27 NaN
28 NaN
29 NaN
... ...
35519 36.0
35520 48.0
35521 45.0
35522 44.0
35523 27.0
35524 26.0
35525 24.0
35526 43.0
35527 NaN
35528 25.0
35529 NaN
35530 NaN
35531 43.0
35532 48.0
35533 56.0
35534 53.0
35535 42.0
35536 46.0
35537 31.0
35538 68.0
35539 23.0
35540 31.0
35541 29.0
35542 34.0
35543 NaN
35544 NaN
35545 NaN
35546 14.0
35547 51.0
35548 NaN
[35549 rows x 9 columns]No temas, todos los datos están ahí, si tu navegas hacía arriba de tu terminal. Seleccionemos solo algunas de las líneas, esto hara más facil que la salida quepa en una terminal, se puede ver que Pandas formateo los datos de tal manera que quepan en la pantalla:
PYTHON
surveys_df.head() # The head() method displays the first several lines of a file. It
# is discussed below.SALIDA
record_id month day year plot_id species_id sex hindfoot_length \
5 6 7 16 1977 1 PF M 14.0
6 7 7 16 1977 2 PE F NaN
7 8 7 16 1977 1 DM M 37.0
8 9 7 16 1977 1 DM F 34.0
9 10 7 16 1977 6 PF F 20.0
weight
5 NaN
6 NaN
7 NaN
8 NaN
9 NaNExplorando los datos del censo de especies
Una vez más podemos usar la función type para ver que
cosa es surveys_df:is:
SALIDA
<class 'pandas.core.frame.DataFrame'>Como podíamos esperar, es un DataFrame (o, usando el
nombre completo por el cual Python usa internamente, un
pandas.core.frame.DataFrame).
¿Qué tipo de cosas surveys_df contiene? Los
DataFrame tienen un atributo llamado
dtypes que contesta esta pregunta:
SALIDA
record_id int64
month int64
day int64
year int64
plot_id int64
species_id object
sex object
hindfoot_length float64
weight float64
dtype: objectTodos los valores de una columna tienen el mismo tipo. Por ejemplo,
months tienen el tipo int64, el cual es un tipo de entero.
Las celdas en la columna de mes no pueden tener valores fraccionarios,
pero las columnas de weight y hindfoot_length
pueden, ya que son de tupo float64. El tipo
object no tiene un nombre muy útil, pero en ete caso
representa una palabra (como ‘M’ y ‘F’ en el caso del sexo).
En otra lección discutiremos sobre el significado de los distintos tipos.
Formas útiles de ver objetos DataFrame en Python
Hay distintas maneras de resumir y accesar a los datos guardados en un DataFrame, usando los atributos y métodos que proveé el objeto DataFrame.
Para accesar a un atributo, se usa el nombre del objeto
DataFrame seguido del nombre del atributo
df_object.attribute. Usando el DataFrame
surveys_df y el atributo columns, un índice de
todos los nombres de las columnas en el DataFrame puede
ser accesado con surveys_df.columns.
Métodos son llamados de la misma manera usando la sintáxis
df_object.method(). Como ejemplo,
surveys_df.head() obtiene las primeros líneas del
DataFrame surveys_df usando el
método head(). Con un método, podemos proporcionar
información extra en los padres para contreol su comportamiento.
Echemos un ojo a los datos usando este.
Reto - DataFrames
Usando nuestro DataFrame surveys_df,
ejecuta los atributos y métodos siguientes y observa que regresan.
surveys_df.columnssurveys_df.shapeToma nota de la salida deshape- ¿Qué formato tiene la salida del atributo que regresa la forma de un DataFrame?
Sugerencia: Más acerca de tuplas, aquí.
surveys_df.head()También ejecutasurveys_df.head(15)¿qué hace esto?surveys_df.tail()
Calculando estadísticas de los datos en un DataFrame de Pandas
Hemos leídos los datos en Python. Ahora calculemos algunas estadísticas para entender un poco de los datos con los que estamos trabajando. Podríamos querer saber cuántos animales fueron colectados en cada sitio, o cuántos de cada especie fueron capturados. Podemos calcular estas estadísticas rápidamente usando grupos. Pero antes tenemos que saber como los queremos argupar.
Empezemos a explorar los datos:
lo que regresa:
SALIDA
Index(['record_id', 'month', 'day', 'year', 'plot_id', 'species_id', 'sex',
'hindfoot_length', 'weight'],
dtype='object')Obtengamos una lista de todas las especies. La función
pd.unique nos dice los distintos valores presentes en la
columnaspecies_id.
lo que regresa:
PYTHON
array(['NL', 'DM', 'PF', 'PE', 'DS', 'PP', 'SH', 'OT', 'DO', 'OX', 'SS',
'OL', 'RM', nan, 'SA', 'PM', 'AH', 'DX', 'AB', 'CB', 'CM', 'CQ',
'RF', 'PC', 'PG', 'PH', 'PU', 'CV', 'UR', 'UP', 'ZL', 'UL', 'CS',
'SC', 'BA', 'SF', 'RO', 'AS', 'SO', 'PI', 'ST', 'CU', 'SU', 'RX',
'PB', 'PL', 'PX', 'CT', 'US'], dtype=object)Reto - Estadísticas
Crear una lista de los IDs de los sitios (“plot_id”) que están en los datos del censo. Llamamemos a esta lista
site_names. ¿Cuántos sitios hay en los datos?, ¿cuántas especies hay en los datos?¿Cuál es la diferencia entre
len(site_names)ysurveys_df['plot_id'].nunique()?
Grupos en Pandas
En algunas ocasiones queremos calcular estadísticas de datos agrupados por subconjuntos o atributos de nuestros datos. Por ejemplo, si queremos calcular el promedio de peso de nuestros individuos por sitio.
Podemos calcular algunas estadísticas básica de todos los datos en una columna usando el siguiente comando:
nos devuelve la siguiente salida
PYTHON
count 32283.000000
mean 42.672428
std 36.631259
min 4.000000
25% 20.000000
50% 37.000000
75% 48.000000
max 280.000000
Name: weight, dtype: float64También podemos extraer una métrica en particular::
PYTHON
surveys_df['weight'].min()
surveys_df['weight'].max()
surveys_df['weight'].mean()
surveys_df['weight'].std()
surveys_df['weight'].count()Pero si nosotros queremos extraer información por una o más
variables, por ejemplo sexo, podemos usar el método
.groupby de Pandas. Una vez que creamos un
DataFrame groupby, podemos calcular estadísticas por el
grupo de nuestra elección.
La función describe de Pandas regresa
estadísticas descriptivas incluyendo: media, meadiana, máx, mín, std y
conteos para una columna en particular de los datos. La función
describe solo regresa los valores de estas estadísticas
para las columnas numéricas.
PYTHON
# Estadísticas para todas las columnas numéricas por sexo
grouped_data.describe()
# Regresa la media de cada columna numérica por sexo
grouped_data.mean()grouped_data.mean() SALIDA:
PYTHON
record_id month day year plot_id \
sex
F 18036.412046 6.583047 16.007138 1990.644997 11.440854
M 17754.835601 6.392668 16.184286 1990.480401 11.098282
hindfoot_length weight
sex
F 28.836780 42.170555
M 29.709578 42.995379El comando groupby es muy potente y no permite
rápidamente generar estadísticas descriptivas.
Reto - Descripción de datos
- ¿Cuántos individuos son hembras
Fy cuántos son machosM? - Qué pasa cuando agrupas sobre dos columnas usando el siguiente enunciado y después tomas los valores medios:
grouped_data2 = surveys_df.groupby(['plot_id','sex'])grouped_data2.mean()
- Calcula las estadísticas descriptivas del peso para cada sitio.
Sugerencia: puedes usar la siguiente sintaxis para solo crear las
estadísticas para una columna de tus datos
by_site['weight'].describe()
Un pedaxo de la salida para el reto 3 se ve así:
SALIDA
site
1 count 1903.000000
mean 51.822911
std 38.176670
min 4.000000
25% 30.000000
50% 44.000000
75% 53.000000
max 231.000000
...Creando estadísticas de conteos rapidamente con Pandas
Ahora contemos el número de muestras de cada especie. Podemos hacer
esto de dsitintas maneras, pero usaremos groupby combinada
con el método count().
PYTHON
# Cuenta el número de muestras por especie
species_counts = surveys_df.groupby('species_id')['record_id'].count()
print(species_counts)O, también podemos contar las líneas que tienen la especie “DO”:
Reto - Haciendo una lista
¿Qué otra manera hay de crear una lista de especies y asociarle
count de las muestras de los datos? Sugerencia: puedes
hacer ejecutar las funciones count, min, etc.
en un DataFrame groupby de la misma manera de la que se
hace en un DataFrame
Graficar rápida y fácilmente los datos usando Pandas
También podemos gráficar nuestras estadísticas descriptivas usando Pandas.
PYTHON
# Aseguremonos de que las imágenes aparezcan insertadas en iPython Notebook
%matplotlib inline
# Creaemos una gráfica de barras
species_counts.plot(kind='bar');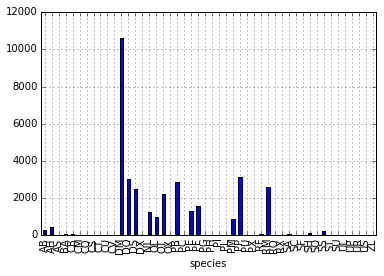 Conteos de especie por sitio
Conteos de especie por sitio
También podemos ver cuantos animales fueron capturados por sitio:
PYTHON
total_count = surveys_df.groupby('plot_id')['record_id'].nunique()
# También grafiquemos eso
total_count.plot(kind='bar');Reto - Gráficas
- Crea una gráfica del promedio de peso de las especies por sitio.
- Crea una gráfica del total de machos contra el total de hembras para todo el conjunto de datos.
Reto de graficación final
Crea una gráfica de barras apiladas con el peso en el eje Y, y la variable de apilamiento que sea el sexo. La gráfica debe mostrar el peso total por sexo para cada sitio. Algúnos tips que te pueden ayudar a resolver el reto son los siguientes:
- Para mayor información en gráfica con Pandas, visita la siguiente liga.
- Puedes usar el siguiente código para crear una gráficad de barras apiladas pero los datos para apilar deben de estar en distintas columnas. Aquí hay un pequeño ejemplo con algunos datos donde ‘a’, ‘b’ y ‘c’ son los grupos, y ‘one’ y ‘two’ son los subgrupos.
PYTHON
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
pd.DataFrame(d)muestra los siguientes datos
SALIDA
one two
a 1 1
b 2 2
c 3 3
d NaN 4Podemos gráficar esto con
PYTHON
# Graficar datos apilados de modo que las columnas 'one' y 'two' estén apiladas
my_df = pd.DataFrame(d)
my_df.plot(kind='bar',stacked=True,title="The title of my graph")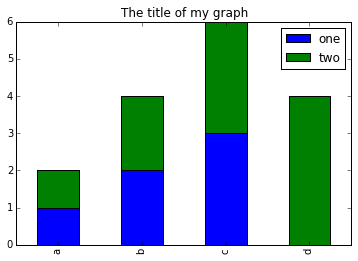
- Podemos usar el método
.unstack()para transformar los datos agrupados en columnas para cada gráfica. Intenta ejecutar.unstack()en algún DataFrame anterior y observa a que lleva.
Empieza transformando los datos agrupados (por sitio y sexo) en una disposición desapilada entonces crea una gráfica apilada.
Primero agrupemos los datos por sitio y por sexo y después calculemos el total para cada sitio.
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()Esto calcula la suma de los pesos para cada sexo por sitio como una tabla
SALIDA
site sex
plot_id sex
1 F 38253
M 59979
2 F 50144
M 57250
3 F 27251
M 28253
4 F 39796
M 49377
<lo demás fue omitido para abreviar>Ahora usaremos .unstack() en los datos agrupados para
entender como el peso total de cada sexo contribuye a cada sitio.
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()
site_sex_count.unstack()El método unstack de arriba despliega la siguiente
salida:
SALIDA
sex F M
plot_id
1 38253 59979
2 50144 57250
3 27251 28253
4 39796 49377
<los demás sitios son omitido por brevedar>Ahora creamos una gráfica de barras apilada con los datos donde el peso para cada sexo es apilado por sitio.
En vez de mostrarla como tabla, nosotros podemos graficar los datos apilando los datos de cada sexo como sigue:
PYTHON
by_site_sex = surveys_df.groupby(['plot_id','sex'])
site_sex_count = by_site_sex['weight'].sum()
spc = site_sex_count.unstack()
s_plot = spc.plot(kind='bar',stacked=True,title="Total weight by site and sex")
s_plot.set_ylabel("Weight")
s_plot.set_xlabel("Plot")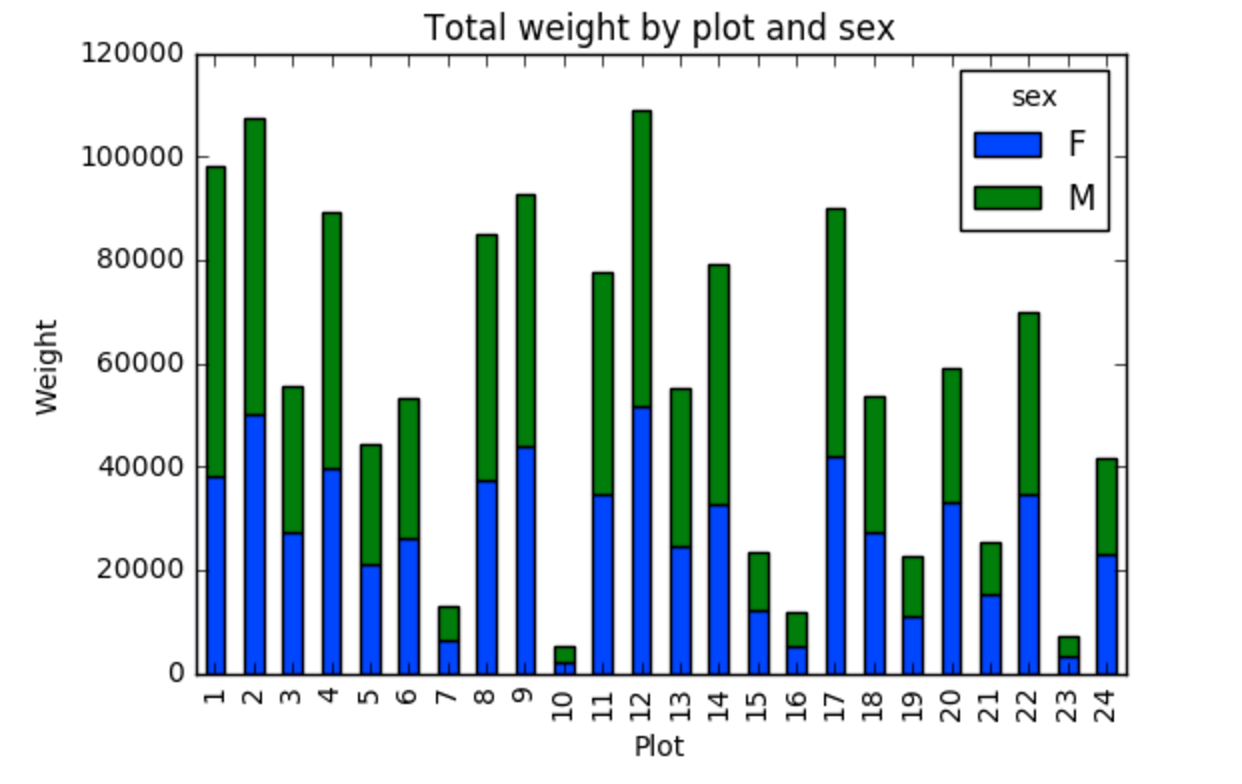
Puntos Clave
- Las bibliotecas en Python son conjuntos de herramientas, funciones y estructuras de datos, agrupadas de forma conveniente para facilitar nuestro trabajo.
- Pandas es una librería que ofrece funcionalidades avanzadas para manejar datos tabulares, procesarlos y obtener resultados similares a los que ofrecen las hojas de cálculo.
- El DataFrame es la estructura de datos fundamental de Pandas, representa una tabla de datos panel con indexación integrada. Cada columna contiene los valores de una variable y cada fila un conjunto de valores de cada columna.
- Un índice es un vector inmutable, ordenado y divisible, que almacena las etiquetas de los ejes de todas las estructuras de Pandas. Se utiliza para agrupar y seleccionar de distintas maneras el contenido de un DataFrame.
- Pandas ofrece funcionalidades que permiten realizar operaciones matemáticas, calcular estadísticas y generar gráficos a partir del contenido de una Serie o DataFrame.