Content from What is a relational database?
Last updated on 2023-05-02 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- What is a relational database?
- What is a table?
- What is a data type?
- Why do tables have key columns?
- What different types of keys are there?
- How does the database represent missing data?
Objectives
- Define a relational database
- Compare with other types of databases
- Understand the structure of a table
- List the SQLite datatypes
- Explain the purpose of a Schema
- Explain Key fields
- Understand the use of NULL
What is a relational database?
A relational database is a collection of data items organised as a set of tables. Relationships can be defined between the data in one table and the data in another or many other tables. The relational database system will provide mechanisms by which you can query the data in the tables, re-assemble the data in various ways without altering the data in the actual tables. This querying is usually done using SQL (Structured Query Language). SQL allows a great many queries to be constructed from the use of only a few keywords. You could have a relational database with only one table, but then you would not have any relationships and it would be more like a spreadsheet. Databases are designed to allow efficient querying against very large tables, more than the 1M rows allowed in an Excel spreadsheet.
What is a table?
As were have noted above, a single table is very much like a spreadsheet. It has rows and it has columns. A row represents a single observation and the columns represents the various variables contained within that observation. Often one or more columns in a row will be designated as a ‘primary key’ This column or combination of columns can be used to uniquely identify a specific row in the table. The columns typically have a name associated with them indicating the variable name. A column always represents the same variable for each row contained in the table. Because of this the data in each column will always be of the same type, such as an Integer or Text, of values for all of the rows in the table. Datatypes are discussed in the next section.
What is a data type?
A data type is a description of the kind of data in a table column. Each database system recognises its own set of datatypes, although some are common to many. Typical examples will be Integer or Text.
The table below gives some examples.
| Data type | Description |
|---|---|
| CHARACTER(n) | Character string. Fixed-length n |
| Text | Character string. Variable length |
| VARCHAR(n) or CHARACTER VARYING(n) | Character string. Variable length. Maximum length n |
| BINARY(n) | Binary string. Fixed-length n |
| BOOLEAN | Stores TRUE or FALSE values |
| VARBINARY(n) or BINARY VARYING(n) | Binary string. Variable length. Maximum length n |
| INTEGER(p) | Integer numerical (no decimal). |
| SMALLINT | Integer numerical (no decimal). |
| INTEGER | Integer numerical (no decimal). |
| BIGINT | Integer numerical (no decimal). |
| DECIMAL(p,s) | Exact numerical, precision p, scale s. |
| NUMERIC(p,s) | Exact numerical, precision p, scale s. (Same as DECIMAL) |
| FLOAT(p) | Approximate numerical, mantissa precision p. A floating number in base 10 exponential notation. |
| REAL | Approximate numerical |
| FLOAT | Approximate numerical |
| DOUBLE PRECISION | Approximate numerical |
| DATE | Stores year, month, and day values |
| TIME | Stores hour, minute, and second values |
| TIMESTAMP | Stores year, month, day, hour, minute, and second values |
| INTERVAL | Composed of a number of integer fields, representing a period of time, depending on the type of interval |
| ARRAY | A set-length and ordered collection of elements |
| MULTISET | A variable-length and unordered collection of elements |
| XML | Stores XML data |
But in practice you can usually restrict your usage to a few
| Data type | Description |
|---|---|
| BOOLEAN | Stores TRUE or FALSE values |
| INTEGER | Integer numerical (no decimal). |
| FLOAT | Approximate numerical |
| DATE | Stores year, month, and day values |
| TIME | Stores hour, minute, and second values |
| TIMESTAMP | Stores year, month, day, hour, minute, and second values |
In SQLite there is only a small number.
| Data type | Description |
|---|---|
| NULL | The value is a NULL value |
| INTEGER | The value is a signed integer, stored in 1, 2, 3, 4, 6, |
| or 8 bytes depending on the magnitude of the value | |
| REAL | The value is a floating point value, stored in 8-bytes |
| TEXT | The value is a text string |
| BLOB | The data is stored exactly as it was input, Used for binary |
| data such as images. |
We won’t be using any BLOB data and it is debatable whether or not NULL should be considered a type at all.
There are some common datatypes which are missing from the SQLite list.
BOOL or BOOLEAN : This type typically accepts values of ‘True’ and ‘False’ In SQLite we would use the Integer type and assign values of 1 to represent ‘True’ and 0 to represent ‘False’.
DATE, DATETIME, TIMESTAMP : SQLite does not have a datatype for storing dates and/or times. You can use TEXT, REAL, or INTEGER values for these and use the built-in Date And Time Functions to manipulate them. We will look at manipulating dates in Lesson 5.
Why do tables have primary key columns?
Whenever you create a table, you will have the option of designating one of the columns as the primary key column. The main property of the primary key column is that the values contained in it must uniquely identify that particular row. That is you cannot have duplicate primary keys. This can be an advantage which adding rows to the table as you will not be allowed to add the same row (or a row with the same primary key) twice.
The primary key column for a table is usually of type Integer although you could have Text. For example if you had a table of car information, then the “Reg_No” column could be made the primary key as it can be used to uniquely identify a particular row in the table.
A table doesn’t have to have a primary key although they are recommended for larger tables. A primary key can also be made up of more than one column, although this is less usual.
What different types of keys are there?
In addition to the primary key, a table may have one or more Foreign keys. A foreign key does not have to be unique or identified as a foreign key when the table is created. A foreign key in one table will relate to the primary key in another table. This allows a relationship to be created between the two tables. If a table needs to be related to several other tables, then there will be a foreign key (column) for each of those tables.
How does the database represent missing data?
All relational database systems have the concept of a NULL value. NULL can be thought of as being of all data types or of no data type at all. It represents something which is simply not known.
When you create a database table, for each column you are allowed to indicate whether or not it can contain the NULL value. Like primary keys, this can be used as a form of data validation.
In many real life situations you will have to accept that the data isn’t perfect and will have to allow for NULL or missing values in your table.
In DB Browser we can indicate how we want NULL values to be displayed. We will use a RED background to the cell to make it stand out. In SQL queries you can specifically test for NULL values.
We will look at missing data in more detail in a later episode.
Key Points
- A relational database is data organised as a collection of related tables
- SQL (Structured Query Language) is used to extract data from the tables. Either a single table or data spread across two or more related tables.
- A schema, which describes the data in a table, has to be created before data can be added
- The schema can be used to provide some data validation on input
Content from Using DB Browser for SQLite
Last updated on 2023-05-02 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- What does the DB Browser for SQLite allow me to do?
Objectives
- Understand the layout of the DB Browser for SQLite and the key facilities that it provides
- Connect to databases
- Create new databases and tables
- Run SQL queries
- Export the results of queries
Launching DB Browser
In Windows the installation of DB Browser does not create a desktop icon. To explicitly launch the application after installing it, use the windows button (bottom left of screen) and type in ‘DB Browser’ in the search bar and selecting the application when it appears.
The Initial screen
The initial screen of DB Browser will look something like this, the panes may be in a different configuration;
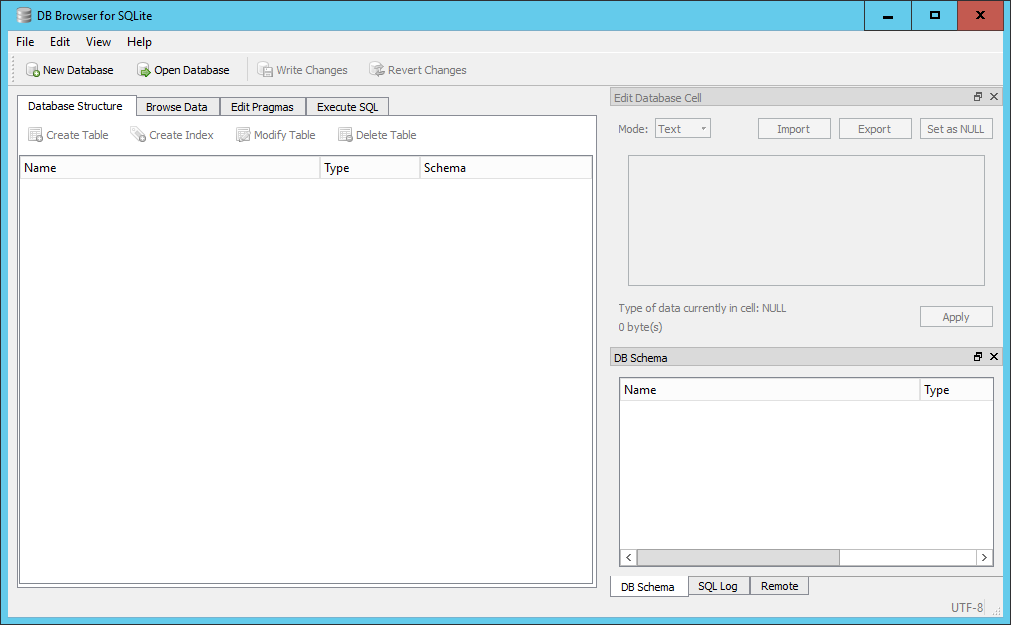
There is;
A small menu system consisting of File, Edit, View and Help. Below the menu system is a toolbar with four options; New Database, Open Database, Write Changes and Revert Changes. Below the toolbar is a 4-tabbed pane for; Database Structure, Browse Data, Edit Pragmas and Execute SQL. Initially these will be quite empty as we haven’t created or opened a database yet. In general we will see how each of these are used as we go through the lesson with the exception of the Edit Pragmas tab which deals with system wide parameters which we won’t want to change.
On the right hand side there are two further panes, at the top is the Edit Database Cell pane which is grayed out. Below it is a 3-tabbed pane for DB Schema, SQL log and Remote. We are only really interested in the DB Schema tab.
Initial changes to the layout.
The overall layout of DB Browser is quite flexible. The panes on the right-hand side can be dragged and dropped into any position, the individual tabs on the bottom pane closed directly from the pane and re-opened from the menu View item.
We will make a couple of initial changes to the layout of the screen. These will be retained across sessions.
- From the View menu item un-select the ‘Edit Database Cell’ icon to the left of the text. This will make the pane close and the bottom pane will be expanded automatically to fill the space.
- On Windows, From the View menu item select ‘preferences’ and select the Data Browser tab.
- On Mac, From the “DB Browser for SQLite” menu item select ‘preferences’ and select the Data Browser tab.
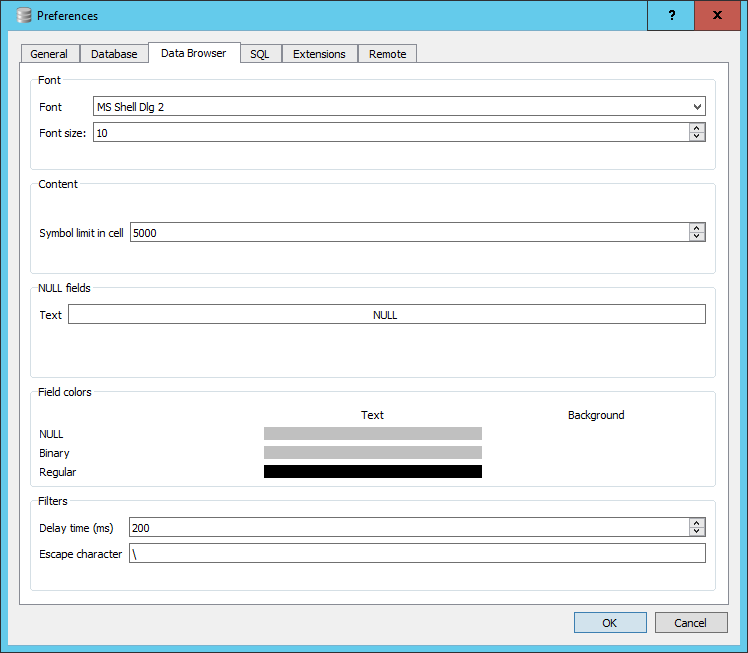
Towards the bottom there is a section dealing with Field colors. You will see three bars below the word Text, to the right there are in fact three invisible bars for the Background. Click in the area for the Background color for NULL. A colour selector window will open, select Red. The bar will turn Red. This is now the default background cell colour that will be used to display NULL values in you tables. We will discuss the meaning of NULL values in a table in a later episode.
You can now close the preference window by clicking OK.
Opening a database
For this lesson we will be making extensive use of the SQL_SAFI database. If you do not already have a copy of this database you can download it from here.
To open the database in DB Browser do the following;
- Click on the ‘open database’ button in the toolbar.
- Navigate to where you have stored the database file on your local machine, select it and click open.
When you open the database, the ‘Database Structure’ tab on the left and the ‘DB Schema’ pane on the right will look very similar. However the ‘DB Schema’ pane is only there to allow you to see the details of the schema for the tables. In particular what tables are in the database and the fields and their types which are in each table.
The ‘Database Structure’ tab on the left allows you to initiate actions on the tables. If you right click on a table name in the ‘DB Schema’ pane, nothing happens. However, if you do the same in the ‘Database Structure’ menu you will be given a set of possible actions. These are the same actions that are available from the toolbar at the top of the tab.
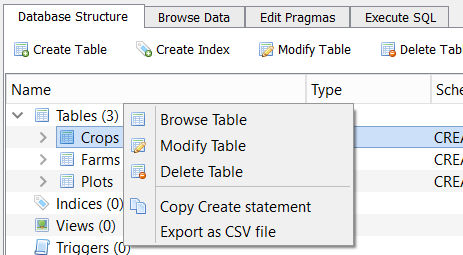
If you select ‘Browse Table’, the data from the table is loaded into the ‘Browse Data’ pane from where it can be examined or filtered. You can also select the table you wish to Browse directly from here.
There are options for ‘New Record’ and ‘Delete Record’. As our interest is in analysing existing data not creating or deleting data, it is unlikely that you will want to use these options.
Running SQL Queries
We will be running queries extensively in future episodes. For now we will just provide an outline of the environment.
In the left hand pane if you select the Execute SQL tab, you will be presented with a three paned window and a small toolbar. The top pane is itself tabbed with the initial tab labeled ‘SQL 1’. This is the SQL editor pane into which you will type your queries.
Below is a simple example query and the results.
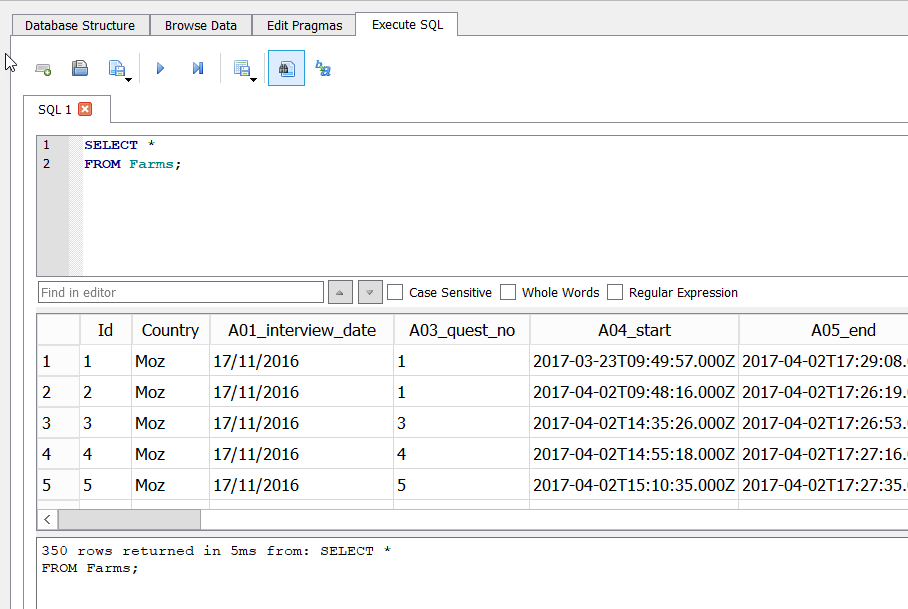
Notice that the query has been written over multiple lines. This is commonly done to aid readability. The second pane has the tabular results, and the bottom pane has a message indicating how many rows were returned, how long it took and a copy of the SQL statement that was executed.
On the toolbar at the top there are eight buttons. Left to right they are:
- Open Tab (creates a new tab in the editor)
- Open SQL file (allows you to load a prepared file of SQL into the editor - the tab takes the name of he file)
- Save SQL file (allows you to save the current contents of the active pane to the local file system)
- Execute SQL (Executes all of the SQL statements in the editor pane)
- Execute current line (Actually executes whatever is selected)
- Save Results (Either to a CSV file or as a database view. We will look at views in a later episode)
- Find (Text in the editor window)
- Find & Replace (Text in the editor window)
Because it is possible to have and execute multiple SQL statements in the same editor pane, each must be terminated with a ‘;’. If you only have a single statement you don’t need it, but it might be considered best practice to always include it.
The pane below the editor is the Results pane. The results of running your query will appear here in a simple tabular format. The bottom pane is for messages about the execution, either an error message or an indication of how many rows were returned by the query.
Creating a database
As well as opening (connecting) to existing databases it is also
possible to create new SQLite databases and tables using DB Browser. To
create a database click the New Database button from the main toolbar
(also available from the File menu). You will initially be asked for a
name for the database and where you want to save it. It is saved as a
single file. You can choose your own extension but ‘sqlite’ is
recommended. If you do not provide a default, then a ‘.db’ extension
will be used. Although the new database is empty, in that there are no
tables in it, the .sqlite file itself is not empty.
Once you have saved the database file the Create Table wizard will open allowing you to create a table. You can cancel this as we will be going through the create table process in a later episode.
Write Changes & Revert Changes
Much of our SQL work involves looking at existing data using SQL queries and possibly writing out the results to a CSV file, in general we will not be changing the contents of the database.
However if, during your DB Browser session, you were to create or delete a table or create a view, then the changes are not automatically written to the database file.
When you try to end the session (i.e. close the application) in which you have made such changes, then you will be asked if you want to save the changes you have made. Alternatively you can explicitly save changes or revert changes during a session by use of the Write Changes and Revert Changes buttons on the toolbar. Once written the changes are permanent (there is no concept of multiple ‘undo’ like you might have in other programs). Revert Changes will take you back to the last Written copy.
Key Points
- The DB Browser for SQLite application allows you to connect to an existing database or create a new database
- When connected to a database you can create new tables
- When connected to a database you can write and run SQL queries and view the results
- You can save the results of a query to a file
Content from The Select Statement
Last updated on 2023-05-02 | Edit this page
Estimated time: 25 minutes
Overview
Questions
- What is SQL?
- How can I return specific columns from a table?
- How can I return specific rows from a table?
Objectives
- Define SQL
- Explain how SQL is used to access relational database tables
- Understand the difference between DDL and DML
- Create simple SQL queries to return rows and columns from existing tables
- Construct more complex logical expressions for use in WHERE clauses
- Return sorted results from a query
Definition of SQL
SQL or Structured Query Language is an international standard for manipulating data in a relational database. Each Relational Database system like Oracle, MySQL or SQLite implements its own variation of the standard.
Fortunately for the types of commands and queries that we will want to write, all of the implementations are much in agreement. The SELECT queries we will be writing to access data in our SQLite database will execute un-altered in many of the other environments.
Essentially you only have to learn SQL once.
SQL and Relational database tables
The strength of SQL is that a single SQL statement or query can request data be returned from one or many of the tables in the database. You can essentially define the relationships between tables on-the-fly as part of your query statement. Relationships between tables are often included as part of the overall database design. In our situation we may be getting an assortment of tables from different sources so being able to imply the relationship as part of the query has definite advantages.
DDL and DML
DDL stands for Data Definition Language. It is the set of SQL commands used to create, alter or delete database objects such as tables.
DML stands for Data Manipulation Language. For our purposes this is the SELECT command which is used to extract data items from one or more of the database tables.
Simple SQL queries using the Select statement
For the rest of this episode we will be looking at the SELECT statement.
To follow along, you should open the DB Browser application and connect to the SQL_SAFI database.
In SQL, querying data is performed by a SELECT statement. A select statement has 6 key components;
SQL
SELECT colnames
FROM tablename
WHERE conditions
GROUP BY colnames
HAVING conditions
ORDER BY colnamesIn practice very few queries will have all of these clauses in them simplifying many queries. On the other hand, conditions in the WHERE clause can be arbitrarily complex and if you need to JOIN two or more tables together then more clauses (JOIN and ON) are needed.
All of the clause names above have been written in uppercase for clarity. SQL is not case sensitive. Neither do you need to write each clause on a new line, but it is often clearer to do so for all but the simplest of queries.
In this episode we will start with the very simple and work our way up to the more complex.
The simplest query is effectively one which returns the contents of the whole table
It is better practice and generally more efficient to explicitly list the column names that you want returned.
The ‘*’ character acts as a wildcard meaning all of the columns but you cannot use it as a general wildcard. So for example, the following is not valid.
If you run it you will get an error. When an error does occur you will see an error message displayed in the bottom pane.
In addition to limiting the columns returned by a query, you can also
limit the rows returned. The simplest case is to say how many rows are
wanted using the LIMIT clause. In the example below only
the first ten rows of the result of the query will be returned. This is
useful if you just want to get a feel for what the data looks like.
SQL
SELECT Id
, B16_years_liv
, B17_parents_liv
, B18_sp_parents_liv
, B19_grand_liv
, B20_sp_grand_liv
FROM Farms
LIMIT 5;Because the query uses several columns (with longish names), for readability they have been set out on separate lines. SQL takes of white space to you are free to arrange the text of the query as you like.
The WHERE clause
Usually you will want to restrict the rows returned based on some criteria. i.e. certain values or ranges within one or more columns.
In this example we are only interested in rows where the value in the B16_years_liv column is greater than 25
In addition to using the ‘>’ we can use many other operators such as <, <=, =, >=, <>
Using more complex logical expressions in the WHERE
clause
We can also use the AND and OR keywords to build more complex selection criteria.
SQL
SELECT Id
FROM Farms
WHERE B17_parents_liv = 'yes'
AND B18_sp_parents_liv = 'yes'
AND B19_grand_liv = 'yes'
AND B20_sp_grand_liv = 'yes'
;Notice that the columns being used in the WHERE clause
do not need to returned as part of the SELECT clause.
You can ensure the precedence of the operators by using brackets. Judicious use of brackets can also aid readability
SQL
SELECT Id
FROM Farms
WHERE (B17_parents_liv = 'yes' OR B18_sp_parents_liv = 'yes') AND B16_years_liv > 60
;To test each of the OR clauses
SQL
SELECT Id
FROM Farms
WHERE B17_parents_liv = 'yes'
;
SELECT Id
FROM Farms
WHERE B18_sp_parents_liv = 'yes'
;
SELECT Id
FROM Farms
WHERE (B17_parents_liv = 'yes' OR B18_sp_parents_liv = 'yes')
;
SELECT Id
FROM Farms
WHERE B16_years_liv > 60
;OR generally creates a less restrictive condition and
AND makes a more restrictive condition.
The following query returns the rows where the value of B16_years_liv is in the range 51 to 59 inclusive.
The same results could be obtained by using the BETWEEN or IN operators
SQL
SELECT Id, B16_years_liv
FROM Farms
WHERE B16_years_liv IN (51, 52, 53, 54, 55, 56, 57, 58, 59)
;The list of values in brackets do not have to be contiguous or even in order.
Exercise
Write a query using the Farms table which returns the columns Id,
A09_village, A11_years_farm, B16_years_liv. We are only interested in
rows where the A09_village value is either ‘God’ or ‘Ruaca’.
Additionally we only want A11_years_farm values in the range 20 to 30
exclusive and B16_years_liv values strictly greater than 40. There are
many ways of doing this, but try to use an inequality, an
IN clause and a BETWEEN clause.
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village IN ('God', 'Ruaca')
AND A11_years_farm BETWEEN 21 AND 29
AND B16_years_liv > 40
;Sorting results
If you want the results of your query to appear in a specific order, you can use the ORDER BY clause
SQL
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm
;By default the SQL assumes Ascending order. You can make this more
explicit by using the ASC or DESC
keywords.
SQL
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm DESC
;You can also order by multiple columns
SQL
SELECT Id, A09_village, A11_years_farm, B16_years_liv
FROM Farms
WHERE A09_village = 'God'
ORDER BY A11_years_farm DESC , B16_years_liv ASC
;Key Points
- Strictly speaking SQL is a standard, not a particular implementation
- SQL implementation are sufficiently close that you only have to learn SQL once
- The DDL constructs are used to create tables and other database objects
- The DML constructs, typically the SELECT statement is used to retrieve data from one or more tables
- The SELECT statement allows you to ‘slice’ and ‘dice’ the columns and rows of the dataset so that the query only returns the data of interest
Content from Missing Data
Last updated on 2023-05-02 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- How can I deal with missing data?
Objectives
- Recognise what the database sees as missing data
- Understand that the original data source may represent missing data differently
- Define strategies for dealing with missing data
How does the database represents missing data
At the beginning of this lesson we noted that all database systems have the concept of a NULL value; Something which is missing and nothing is known about it.
In DB Browser we can choose how we want NULLs in a table to be
displayed. When we had our initial look at DB Browser, we used the
View | Preference option to change the background colour of
cells in a table which has a NULL values as
red. The example below, using the ‘Browse data’ tab,
shows a section of the Farms table in the SQL_SAFI database showing
column values which are NULL.
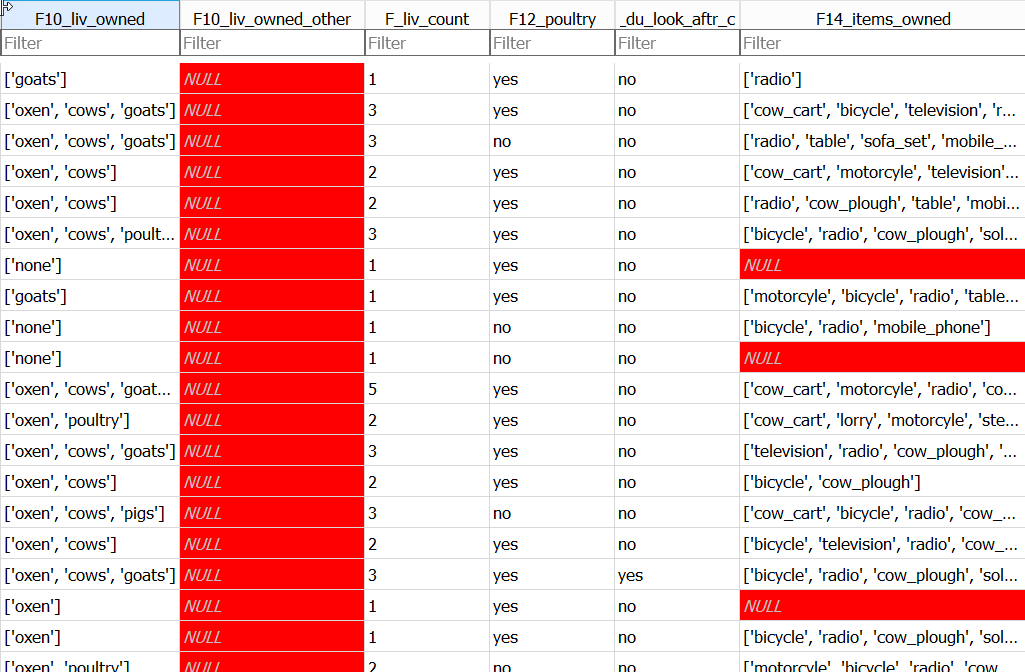
If you type ‘=NULL’ in the filter box for
F14_items_owned, only the rows with NULL in
F14_items_owned will be displayed.
You can get the same results using the following query;
SELECT *
FROM Farms
WHERE F14_items_owned IS NULL
;Notice that we use IS and not =. This is
because ‘NULL’ equals nothing and everything all at the same time!
This table was created from a csv file, part of which looks like this
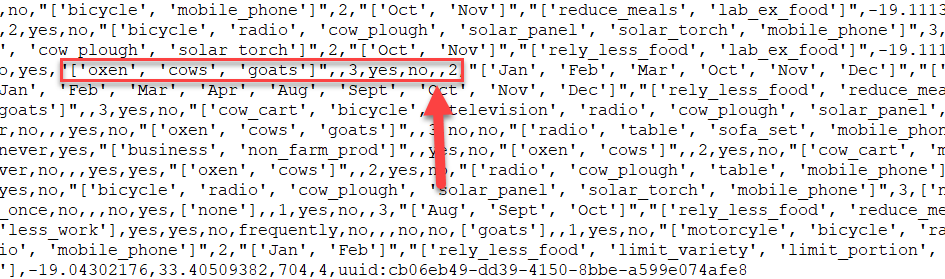
The highlighted area shows part of the record with Id = 21, the second record returned by the query. It starts with the ‘F10_liv_owned’ column and ends with the ‘G01_no_meals’ column. The Arrow points to the two consecutive ‘,’s representing the lack of a value for the ’F14_items_owned’ column. These values are missing from the data.
Reasons for Missing data
There can be many reasons why data is missing; Not collected, lost, Not applicable etc. In the case of our Farms table, many of the missing values have occurred as a result of the survey design.
If you run the following query :
The first part of the results will look like this:
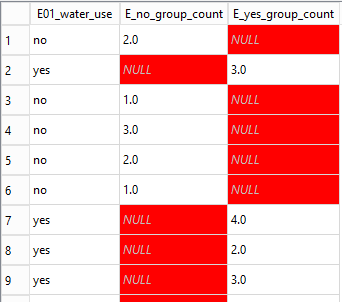
You may be able to spot from this the relationship between the values
in the E01_water_use column and whether or not there is a
NULL value in either the E_no_group_count or
the E_yes_group_count column.
Only if the Farmer said that they did use water (E01_water_use =
‘yes’) they were asked how many plots they used water on and the value
stored in E_yes_group_count otherwise this field was not even presented
in the survey and so contains a NULL value. In this
situation we expect NULL values and they will not cause any
problems.
However the F14_items_owned column records the
possessions of the Farmer. This question was always asked. It is not
clear from the NULL values we find in this field whether or
not it means ‘I have no possessions’ or ‘I do not wish to tell you what
possessions I have’, in short, we know nothing about the items owned and
therefore the value of NULL is appropriate.
Dealing with missing data
There are several statistical techniques that can be used to allow
for NULL values, which one you might will depend on what
has caused the NULL value to be recorded.
You may want to change the NULL value to something else.
For example if we knew that the NULL values in the
F14_items_owned column actually meant that the Farmer had
no possessions then we might want to change the NULL values
to ‘[]’ to represent and empty list. We can do that in SQL with an
UPDATE query.
The update query is shown below. We are not going to run it as it would change our data. You need to be very sure of the effect you are going to have before you change data in this way.
Rather than changing the data we may just want to miss it out of our analysis.
We can write a query which excludes the rows where
F14_items_owned has a NULL value with:
Key Points
- You should expect missing data
- You need to know how missing data is being represented in your dataset
- Database systems always represent what they consider to be missing
data as
NULL - You can explicitly test for
NULLvalues in your data - You may need other tests for different representations of
NULL
Content from Creating New Columns
Last updated on 2023-05-02 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- How can I add new columns with derived values in the query results?
- How can I give a column a new name?
- How do I use built-in functions to create new values?
- How can I create binned results?
Objectives
- Create new columns in the query output
- Rename columns in the query output
- Use built-in functions to create new values
- Use SQL syntax to conditionally create new values
- Use SQL syntax to create a new column of ‘binned’ values
Creating new columns
In addition to selecting existing columns from a table, you can also create new columns in the query output based on the existing columns. These new columns only exist in the output. The table used in the query is not changed in any way.
The Plots table contains a column, D02_total_plot
representing the area of the plot and the D03_unit_land
column gives the units. In our sample dataset the unit is always
‘hectare’. However in the full dataset some of the plot areas are
recorded in ‘acres’. We want to create a new output column which shows
the hectare value converted into acres. To do this we could use the
following SQL. ( 1 hectare = 2.4701 acres)
Running this query will give the correct answers, but it uses the expression used in creating the new column as the column name. This looks very messy, especially if the expression is long. It is always the case that if you create a column in the results of the query it won’t have a name by default. SQL will create one for it. Other relational databases take different approaches to the problem and will pseudo-randomly name the new columns for you with such things as ‘_c0’. SQLite uses the expression you used to create the column name.
Renaming columns using aliases
Given that creating new columns is so commonly done, SQL does provide a mechanism for giving them names of your choice. This is done using the AS clause
The AS keyword itself is optional. You can just put the name of the new column, but using the AS keyword adds clarity. Creating column names in this way is referred to as adding an alias. This may seem a bit strange for columns which had no real name in the first place, but the point is, you can give any table column name an alias to be used in the output rather than the original.
Using built-in functions to create new values
In addition to using simple arithmetic operations to create new columns, you can also use some of the SQLite built-in functions. Full details of the available built-in functions are available from the SQLite.org website here.
We will look at some of the arithmetic and statistical functions when we deal with aggregations in a later lesson.
You may have noticed in the output from are last query that the
number of decimal places can change from one row to another. In order to
make the output more tidy, we may wish to always produce the same number
of decimal places, e.g. 2. We can do this using the ROUND
function.
The ROUND function works in a similar way as its
spreadsheet equivalent, you specify the value you wish to round and the
required number of decimal places.
SQL
SELECT Id, plot_Id, D01_curr_plot, D02_total_plot,
ROUND(D02_total_plot * 2.4701, 2) AS D02_total_plot_converted,
'acres' AS D03_unit_land_converted
FROM Plots
;Notice that we can use columns as part of the calculated column which are not returned in the output. Also our second new column doesn’t actually need to make use of any of the other columns, it can just be a value.
We will now look at a couple of the more common text functions. These have equivalents in other programming languages or spreadsheet systems, sometimes with different names.
| SQLite function | Excel equivalent |
|---|---|
| substr(a,b,c) | mid(a,b,c) |
| instr(a,b) | find(a,b) |
instr can be used to check a character or string of
characters occurs within another string. substr can be used
to extract a portion of a string based on a starting position and the
number of characters required.
In the Farms table, the three columns A01_interview_date, A04_start
and A05_end are all recognisable as a dates with the A04_start and
A05_end also including times. These last two are automatically generated
by the eSurvey software when the data is collected, i.e. they are
automatically entered. The A01_interview_date however is manually input.
In all three cases however SQLite thinks that they are all just strings
of characters. We can confirm this by selecting the
Database Structure tab and expanding the Farms
entry and notice that the data type for all three columns is listed as
‘TEXT’
To see what these columns look like you can run the following query;
The format of the A04_start and A05_end columns follow the ISO 8601. The A01_interview_date column on the other hand uses the shorthand dd/mm/yyyy format.
The drawback of having dates represented by strings occurs when you
want to sort them. In SQL you can sort the output of your query by using
an ORDER BY clause at the end of the select statement.
NB. we are using the UK and European representation of dates in this discussion. The same issue will occur if you were using US date formats.
It is unlikely that the result of the above query is what you wanted. ‘01/07/2017’ has been ordered before ‘01/12/2016’. This is because the sorting process treats the dates as simple strings and a ‘0’ in the month position is less than a ‘1’ in the months position.
In order to sort the A01_interview_date column into date order we need to make SQLite see it as a date. SQLite does have a date function. Unfortunately by itself, it won’t work on A01_interview_date.
SQL
SELECT A01_interview_date,
date(A01_interview_date) AS converted_A01,
A04_start,
date(A04_start) AS coverted_A04
FROM Farms
;Although it doesn’t produce an error, the attempted conversion of A01_interview_date into a date format has failed. A set of NULLs was returned.
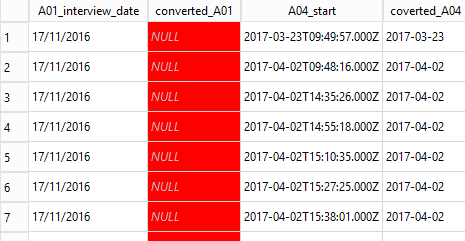
On the other hand the A04_start conversion did work. The problem is that the date function expects the string to be converted to be in a certain format like ISO-8601.
We need to change the way A01_interview_date looks. Instead of
dd/mm/yyyy we need yyyy-mm-dd. To do this we can use the
substr function along with the || operator
which is used to concatenate strings together.
We can extract individual parts of the date like this;
SQL
SELECT A01_interview_date,
substr(A01_interview_date,7,4) as year,
substr(A01_interview_date,4,2) as month,
substr(A01_interview_date,1,2) as day
FROM Farms
;But in order to convert it into a date we need all three parts concatenated together along with ‘-’ to separate the parts.
SQL
SELECT A01_interview_date,
substr(A01_interview_date,7,4) || '-' ||
substr(A01_interview_date,4,2) || '-' ||
substr(A01_interview_date,1,2) as converted_date
FROM Farms
;We can then convert our new string containing the date into a proper
date by passing it to the date function.
SQL
SELECT A01_interview_date,
date(
substr(A01_interview_date,7,4) || '-' ||
substr(A01_interview_date,4,2) || '-' ||
substr(A01_interview_date,1,2)
) as converted_date
FROM Farms
;We can now use our converted_date column to sort by
SQL
SELECT A01_interview_date,
date(
substr(A01_interview_date,7,4) || '-' ||
substr(A01_interview_date,4,2) || '-' ||
substr(A01_interview_date,1,2)
) as converted_date
FROM Farms
ORDER BY converted_date
;In the Spreadsheets lesson we discussed that splitting dates into year, month and day components was a good way of making the meaning of the date parts unambiguous. Our first SQL query for the date conversion did this;
SQL
SELECT A01_interview_date,
substr(A01_interview_date,7,4) as year,
substr(A01_interview_date,4,2) as month,
substr(A01_interview_date,1,2) as day
FROM Farms
;Having the date components split in this way does not prevent us from sorting them. We just need to specify all of the columns we want to sort by in the order in which we want them sorted.
SQL
SELECT A01_interview_date,
substr(A01_interview_date,7,4) as year,
substr(A01_interview_date,4,2) as month,
substr(A01_interview_date,1,2) as day
FROM Farms
ORDER BY year, month, day
;By default the ORDER BY clause will sort in ascending
order, smallest to biggest; we can make this explicit by usingthe
ASC keyword. Or if we want to sort in descending order we
can use the DESC keyword.
Using SQL syntax to conditionally create new values
This format of the case statement allows you to check if various
values are equal to the value in the field given after
the CASE keyword.
SQL
SELECT Id, country,
CASE country
WHEN 'Moz' THEN 'Mozambique'
WHEN 'Taz' THEN 'Tanzania'
ELSE 'Unknown Country'
END AS country_fullname
FROM Farms
;There is a more general form which allows to to perform any kind of test.
Using SQL syntax to create ‘binned’ values
It is often the case that we wish to convert a continuous variable into a discrete factor type variable.
We can use a CASE statement to create this type of
effect.
The column A11_years_farm in the Farms table is an
indication of how many years the respondent has been on the farm. The
values are in years and range from 1 to 60. Instead of using individual
years we may want to group these values into ranges like 1-10, 11-20
etc. We can do this using a CASE statement as part of the
SELECT clause
SQL
SELECT Id, A11_years_farm,
CASE
WHEN A11_years_farm BETWEEN 1 AND 10 THEN '1-10'
WHEN A11_years_farm BETWEEN 11 AND 20 THEN '11-20'
WHEN A11_years_farm BETWEEN 21 AND 30 THEN '21-30'
WHEN A11_years_farm BETWEEN 31 AND 40 THEN '31-40'
WHEN A11_years_farm BETWEEN 41 AND 50 THEN '41-50'
WHEN A11_years_farm BETWEEN 41 AND 50 THEN '51-60'
ELSE '> 60'
END AS A11_years_farm_range
FROM Farms
;Content from Aggregations
Last updated on 2023-05-02 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- How can I summarise the data in my tables
Objectives
- Use the Distinct keyword to get a unique set of values
- Use the ‘group by’ clause to summarise data
- Use built-in statistical functions to provide column summaries
- Use the ‘having’ clause to provide selection criteria to the summary values
- Understand the difference between the ‘where’ and the ‘having’ clauses
Using built-in statistical functions
Aggregate functions are used perform some kind of mathematical or statistical calculation across a group of rows. The rows in each group are determined by the different values in a specified column or columns. Alternatively you can aggregate across the entire table.
If we wanted to know the minimum, average and maximum values of the ‘A11_years_farm’ column across the whole Farms table, we could write a query such as this;
This sort of query provides us with a general view of the values for a particular column or field across the whole table.
min , max and avg are built-in
aggregate functions in SQLite (and any other SQL database system). There
are other such functions available. A complete list can be found in the
SQLite documentation here.
It is more likely that we would want to find such values for a range, or multiple ranges of rows where each range is determined by the values of some other column in the table. Before we do this we will look at how we can find out what different values are contained in a given column.
The DISTINCT keyword
For the SAFI survey, it was known in advance all of the possible values that certain variables of columns could contain. For example the ‘A06_province’, ‘A07_district’, ‘A08_ward’ and ‘A09_village’ variables could only ever contain a few specific values.
As the SAFI survey was delivered via an Android phone app. It was possible to create the app so that the possible values could be selected from a dropdown list, eliminating any possibility of typing errors. For the ‘A06_province’ there were only three possibilities, but by the time we get down to ‘A09_villages’, a far more specific geography, it would not have been possible to anticipate in advance all of the possible values (village names) and so the values for this field were manually typed in.
To obtain a list of unique values in a particular column we can use
the DISTINCT keyword.
Using the Farms table we will obtain a list of all of the different values of the ‘A06_province’ column contained in the table.
We can see from the results of running this that all 3 values are represented and that there is no missing data in this field.
However if we run a similar query for ‘A09_village’
We get

The problem with allowing free-form text quite obvious. Having two villages, one called ‘Massequece’ and the other called ‘Massequese’ is unlikely.
Detecting this type of problem in a large dataset can be very difficult if you are just ‘eyeballing’ the content. This small SQL query makes it very clear, and in the OpenRefine lesson we provide approaches to detecting and correcting such errors. SQL is not the best tool for correcting this type of error.
You can have more than one column name after the
DISTINCT keyword. In which case the results will include a
row for each unique combination of the columns
involved
Exercise
Write a query that will return all of the different combinations of the ‘A06_province’, ‘A07_district’, ‘A08_ward’ and ‘A09_village’ columns in the Farms table.
When looking at the results, you may have noticed that they are not in any sorted order. Re-write the query so that the values of the four columns are returned in alphabetical order.
The GROUP BY clause to summarise data
Just knowing the combinations is of limited use. You really want to
know How many of each of the values there are. To do
this we use the GROUP BY clause.
This query tells us how many records in the table have each different value in the ‘A08_ward’ column.
In the first example of this episode, three aggregations were
performed over the single column ‘A11_years_farm’. In addition to
calculating multiple aggregation values over a single column, it is also
possible to aggregate over multiple columns by specifying them in all in
the SELECT clause and the
GROUP BY clause.
The grouping will take place based on the order of the columns listed
in the GROUP BY clause. There will be one row returned for
each unique combination of the columns mentioned in the
GROUP BY clause
What is not allowed is specifying a non-aggregated column in the select clause which is not mentioned in the group by clause.
SQL
SELECT A06_province,
A07_district,
A08_ward,
A09_village,
count(*) AS How_many
FROM Farms
GROUP BY A06_province, A07_district, A08_ward, A09_village
;SELECT A09_village,
min(A11_years_farm) AS min,
max(A11_years_farm) AS max,
avg(A11_years_farm) AS avg,
count(*) AS how_many
FROM Farms
WHERE A07_district = 'Nhamatanda'
GROUP BY A09_village;Notice that you can use the ‘A07_district’ column in the
WHERE clause but it doesn’t have to appear in the
SELECT clause.
Using the HAVING clause
In order to filter the rows returned in a non-aggregated query we
used the WHERE clause. For an aggregated query the
equivalent is the HAVING clause.
You use the HAVING clause by providing it with a filter
expression which references one or more of the aggregated columns.
In a HAVING clause you can use the column alias to refer
to the aggregated column.
SQL
SELECT A08_ward,
min(A11_years_farm) AS min_years,
max(A11_years_farm) AS max_years,
count(*) AS how_many_farms
FROM Farms
GROUP BY A08_ward
HAVING how_many_farms > 2;In this example we want to remove the wards which only have one or two farms.
Content from Creating tables and views
Last updated on 2023-05-02 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- What is the difference between a table and a view?
- How can I create a table using the DB Browser for SQLite?
- How can I create a table or view in DB Browser for SQLite using SQL code?
- How can I add records of data to a table?
Objectives
- Understand the differences and similarities between Tables and Views
- Create table schemas using DB Browser for SQLite
- Create table schemas and views using SQL code
- Populate a table using SQL code
- Populate a table from a file of data using DB Browser for SQLite
Using SQL code to create tables
In relational databases, tables have to be created before you can add data to them. The table definition that you create is referred to as the Schema of the table.
The schema can contain many different properties of the table and the data that it does/will contain. In its simplest form you only need to specify a name for the table and a list of the column names and the data types for each of those columns.
In this episode we will also show how the Farms, Plots and Crops tables were created and populated from csv files. When we do this using DB Browser, it appears to be a single step process, much like importing a file into Excel. In fact it is always a two step process. First……………
Using the DB Browser application to create tables
So far we have created and populated tables from scratch or created tables from existing tables. But initially your data is likely to be external to the relational database system in a set of simple files. Typically in CSV (comma separated values) or Tab delimited format.
All relational database systems will have some utility which will allow you to import such files into tables in the database. The DB Browser application has a nice GUI (Graphical Use Interface) to allow you to do this.
The Farms, Plots and Crops tables that we have been using were created in the DB Browser application by importing a CSV file containing the data.
For large datasets this is a very common approach.
From the File menu select ‘Import’ and then ‘Table from CSV file’. This will start the ‘Import CSV file’ wizard and you will be asked to select the file of data you wish to import from a standard Windows file open dialog.
After you have selected the file, you will be shown the ‘Import CSV file’ window which will allow you to set a name for the table (the default is taken from the filename). You will see the first few rows of the data and there are a few options which can be changed if needs be.
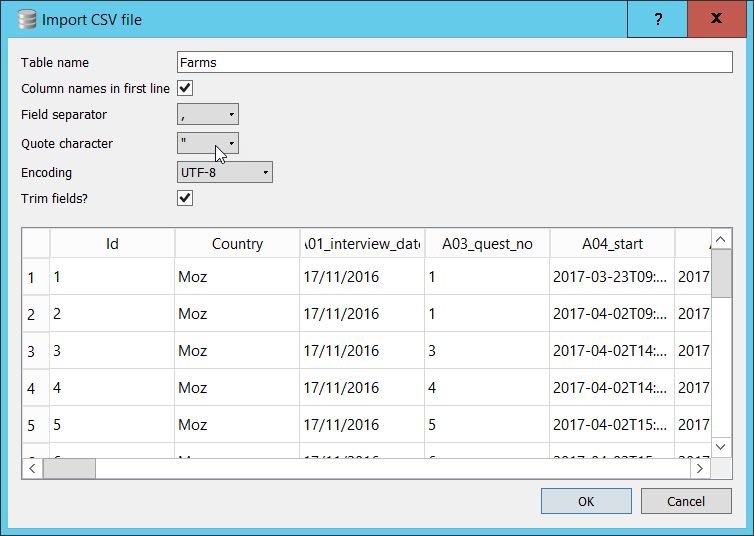
In our case all of the options are correctly set. If your file was in Tab delimited format, you would need to change the ‘Field separator’ option to ‘Tab’. If your file did not have a header row with column names you would un-check the appropriate box and DB Browser will allocate names for the columns. (You can change them to more meaningful names yourself after the import is complete)
- When you click OK, a table will be created and the data loaded into the table.
Unfortunately this Import wizard in DB Browser does not do, or allow you to do everything that you might want when creating a table. The most obvious potential problem is that we were not allowed to specify the data types to be associated with each of the columns in the table. However, DB Browser will attempt to work out the appropriate data types based on the values in the first few rows of the data. This is a very common approach. (Earlier versions of DB Browser didn’t do this, it just imported all of the columns as ‘Text’ data types.) If you go to the table in the Database Structure tab and click the ‘>’ you will see all of the fields and they are all listed as either Text or Integer fields.
If any of the datatypes are not as expected or wanted we can change them.
- Select the newly created table in Database Structure tab and click the ‘Modify Table’ button in the toolbar. The ‘Edit Table Definition’ dialog will appear.
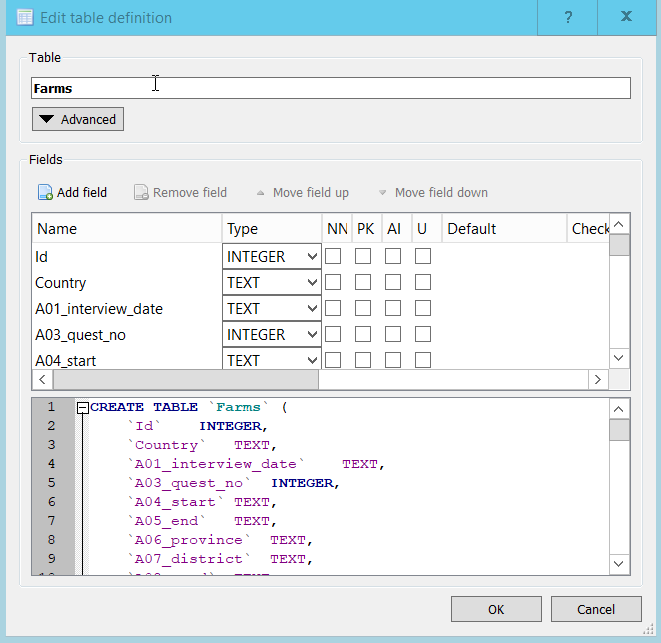
In this particular case DB Browser correctly selected the datatypes.
Notice that the A01_interview_date was allocated a datatype
of ‘TEXT’. This isn’t a problem as we have to use the Date and Time
functions to manipulate dates anyway.
Notice that the bottom pane in the Window shows the SQL DDL statement that would create the table that you modifying.
When you change one of the columns from TEXT to INTEGER, this is
immediately reflected in the Create Table statement.
It is slightly misleading because in fact we are modifying an existing
table and in SQL-speak, this would be an Alter Table…
statement. However it does illustrate quite well the fact that whatever
you do in the GUI, it is essentially translated into an SQL statement
and executed. You could copy and paste this definition into the SQL
editor and if you change the table name before you ran it, you would
create a new table with that name. This new table would have no data in
it. This is how the insert table wizard works. It uses the header row
from your data to create a CREATE TABLE statement which it
runs. It then transforms each of the rows of data into SQL
INSERT INTO... statements which it also runs to get the
data into the table.
In addition to changing the data types there are several other options which can be set when you are creating of modifying a table. For our tables we don’t need to make use of them but for completeness we will describe what they are;
PK - Or Primary Key, a unique identifier for the
row. In the Farms table, there is an Id column which
uniquely identifies a Farm. This could act as a unique identifier for
the row as a whole. We could mark this as the primary key if we wanted
to.
AI - Or Auto Increment. This isn’t really applicable to tables created in this way, i.e. the creation of the schema immediately followed by loading data from a file. It is usually used to generate unique values for a column which could then act as a primary key. If you have an ‘Auto Increment’ column in a table, when you insert values you would not supply a value for the column as SQLite will automatically provide a value for each row added.
Not Null - If this is checked then it means that there must be a value for each row in this column. If it is not set and there is no value provided in the data then it will be set to ‘NULL’ which means ‘I know nothing about what should be here’. (Not the string ‘NULL’ but the NULL value)
In real datasets missing values are quite common and we have already looked at ways of dealing with them when they occur in tables. If you were to check this box and the data did have missing values for this column, the record from the file would be rejected and the load of the file will fail.
U - Or Unique. This allows you to say that the contents of the column, which is not the primary key column has to have unique values in it. Like Allow Null this is another way of providing some data validation as the data is imported. Although it doesn’t really apply with the DB Browser import wizard as the data is imported before you are allowed to set this option.
Default - This is used in conjunction with ‘Not Null’, if a value is not provided in the dataset, then if provided, the default value for that column will be used.
Check - This allows you to specify a constraint on the values entered for the column. You could restrict the range of values or compare the value with other columns values.
These three options, ‘Not Null’, ‘Unique’ and ‘Default’ , need to be used with caution and certainly their use needs to be fully documented and explained.
Creating a table using an SQL command
You could copy and paste this definition into the SQL editor and if
you change the table name before you ran it, you would create a new
table with that name. This new table would have no data in it. This is
how the insert table wizard works. It uses the header row from your data
to create a CREATE TABLE statement which it runs. It then
transforms each of the rows of data into SQL INSERT INTO...
statements which it also runs to get the data into the table.
For small tables defining them and populating them with data in this way may be acceptable. But for larger tables this approach not only to defining the tables but adding potentially thousands of rows of data can be somewhat impractical.
Creating tables from other tables
Whenever you write a Select query and run it, the results are always in the form of a table. In the results pane, you can see the column names and the rows of data in the results.
This provides a very easy way of creating a new table based on the results of a query.
The following query selects a few of the columns from the Farms table:
If you want to make the results of this query into a new table, you
can do so by simply prefixing the SELECT with
CREATE TABLE NewTablename AS like this:
SQL
CREATE TABLE Farms_location AS
SELECT Id,
Country,
A06_province,
A07_district,
A08_ward,
A09_village
FROM Farms;If we wanted to create a table from the Crops table which contains only the rows where the D_curr_crop value was ‘rice’ we could use a query like this:
Here we want all of the columns from the Crops table but only if the D_curr_crop value is ‘rice’.
Note: please ensure that you run the code above as we will use this new table in a later episode.
Using SQL code to create views
In addition to tables all relational database systems have the
concept of ‘Views’. Views are based on tables. In the same way that we
were able to create a table based on a SELECT query, we can
create a ‘View’ in the same way. You just replace ‘Table’ with
‘View’.
SQL
CREATE VIEW Farms_location AS
SELECT Id,
Country,
A06_province,
A07_district,
A08_ward,
A09_village
FROM Farms;Tables and Views are so closely related that if you try to run the code above, although ‘Table’ has been changed to ‘View’ you will get an error complaining that the ‘Table’ already exists.
It is common practice when creating Views to indicate somewhere in the name that it is in fact a View. e.g. vFarms_location or Farms_location_v.
Although tables and views can be used almost interchangeably in
SELECT queries it is important to note that a
View unlike a Table contains no data. It is
essentially the SQL statement needed to produce that data from the
underlying data. This means that when you use a View there is the
overhead of having to run this SQL first. Although in practice the
Database system will combine the SQL required by the View and the other
SQL in your query so as to optimise how the SQL is executed.
The advantage of using Views is that it allows you to restrict how you see the data in a table. In the example we used above it may be far easier to work with only the 6 columns that we need from the full Farms table rather than the full table with 61 columns.
A View isn’t restricted to simple SELECT statements it
can be the result of aggregations and joins as well. This can help
reduce the complexity of queries based on the View and so aid
readability.
Key Points
- Database tables can be created using the DDL command
CREATE TABLE - They can be populated using the
INSERT INTOcommand - The SQLite plugin allows you to create a table and import data into it in one step
- There are many options available to the
CREATE TABLEcommand which allows greater control over how or what data can be loaded into the table - A View can be treated just like a table in a query
- A View does not contain data like a table does, only the instructions on how to get the data
Content from The SQLite command line
Last updated on 2023-05-02 | Edit this page
Estimated time: 25 minutes
Overview
Questions
- How can I save my code in a file and run it again?
Objectives
- Use the SQLite shell to re-run a file of SQL code
- Save the output from the SQLite shell to a file
Running SQL code using the SQLite shell
Before you can run the SQLite3 shell program you must have installed it. Instructions for doing this are included in the set up procedures.
I will assume that you have added the location of the program to your local PATH environment variable as this will make it easier to refer to the database file and other files we may want to use.
The instructions in this episode are written from a Windows user perspective. If you are using Linux or a Mac, open a terminal window instead a command prompt.
- Open a command prompt (cmd.exe) and ‘cd’ to the folder location of the SQL_SAFI.sqlite database file.
- run the command ‘sqlite3’ This should open the SQLite shell and present a screen similar to that below.
- By default a “transient in-memory database” is opened. You can change the database by use of the .open command
It is important to remember the .sqlite suffix, otherwise a new database simply called SQL_SAFI would be created
- Once the database is opened you can run queries by typing directly in the shell. Unlike in DB Browser, you must always terminate your select command with a “;”. This is how the shell knows that You think the statement is complete. Although easy to forget, it generally works to your advantage as it allows you to split a long query command across lines as you did in the DB Browser application.
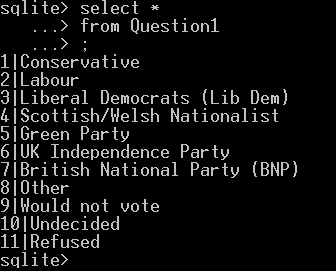
The output from the query is displayed on the screen. If we just wanted to look at a small selection of data this may be OK. It is however more likely that not only are the results from the query somewhat larger, but also we would prefer to save the output to a file for later use. There are some other changes to the output format that we might want to change as well. for example; change the field separator from the default “|” to a comma and provide column headers. This will make the output more like a standard csv file.
Notice that the NULL values in columns 6 and 8 are just
left empty, two consecutive delimiters, just as they are in a csv
file.
We can make the changes we want by using further “dot” commands.
There are in fact a large number of “dot” commands and they are all
explained in the official SQLite documentation here. One you will have to use at
some point is .quit which will end the SQLIte shell
program.
The commands we need are
to change the field separator to “,”. There are many other modes available see the documentation.
to show the column headers
to direct the output to a file of my choice. The file will be created if needed or it will overwrite an already existing file, so exercise care.
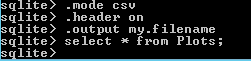
Yes you can have a file called “my.filename” if you want. The contents of which contains the expected output from the query.
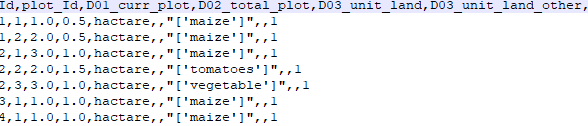
Notice the use of quotes in the rows where the value of the data item themselves contain quotes; in this case single quotes.
Automating the use of the SQLite shell
So far we have used the shell in much the same way as we might have used the DB Browser application. We run the program, connect to a database, run a query and save the output. Because the shell will accept any valid SQL statements as well as have numerous ‘dot’ commands of it own to configure how it works it could be considered as powerful as the DB Browser application. You could use it as a replacement in most cases.
Most people prefer to work with nice point and click interfaces, so why would you want to use the shell rather than the DB Browser application?
The shell has one distinct advantage over DB Browser; you can run the shell program and in the call to the program provide a parameter indicating the database to connect to and provide a file of the commands that you want to execute. The shell will execute the file of commands and then exit.
Here is an example
- create a file
commands.sqlcontaining the following content:
SQL
result.csv
.mode csv
.output results.csv
.open SQL_SAFI.sqlite
SELECT * from Farms where A09_village='God';- run the sqlite3 program in the following way
Notice that there is no output to the screen and that the shell is closed. The results of running the query have been placed in the results.csv file.
There are two key advantages of using this approach.
It aids automation. It would be straightforward to have the one line command line instruction to be run automatically, perhaps on a timed basis. The SQL statements in the executed file doesn’t have to be a simple query. It could be appending rows of data to a series of tables which become available on a regular basis.
It aids reproducibility. Although it is convenient to use the DB Browser application to play around and try things out, eventually you will decide on approach, create relevant queries to perform your analysis or research and at this point you will need to ensure that the complete sequence is documented and is reproducible. This is what the file of SQLite commands will do for you.
Exercise
The query
returns all of the records from the Farms table which have a roof made of grass.
Create a file of SQL statements and SQLite shell commands to create 3 files each containing the output from queries like the above but for all three different roof types (grass, mabatisloping and mabatipitched)
The contents of your file should be something like this:
OUTPUT
.mode csv
.output grass_roofs.csv
select * from Farms where C01_respondent_roof_type = 'grass';
.output mabatisloping_roofs.csv
select * from Farms where C01_respondent_roof_type = 'mabatisloping';
.output mabatipitched_roofs.csv
select * from Farms where C01_respondent_roof_type = 'mabatipitched';The command to run it from the command line is:
Key Points
- SQLite databases can be created, managed and queried from the SQLite shell utility
- You can run the shell interactively from the command line, typing queries or dot commands at the prompt
- You can call the SQLite3 program and specify a database and a set of commands to run. This aids automation
Content from Joins
Last updated on 2023-05-02 | Edit this page
Estimated time: 30 minutes
Overview
Questions
- What is meant by joining tables?
- Why would I want to join tables?
- What different types of joins are there?
- How do Joins help you discover missing data or gaps in the data
Objectives
- Understand the structure of a joined table
- Familiarity with the different join types
- Use different join types in analysing your data
- Understand what other join types can tell you about your data
About table joins
In any relational database system, the ability to join tables together is a key querying requirement. Joins are used to combine the columns from two (or more) tables together to form a single table. A join between tables will only be possible if they have at least one column in common. The column doesn’t have to have the same name in each table, and quite often they won’t, but they do have to have a common usage.
In the SAFI database we have three tables. Farms, Plots and Crops. Each farm has a number of plots (or fields) and each plot can be used to grow different crops. A question you might ask is: Which Farms with more than 12 people in the household grow Maize? No single table has the answer to this question.
We can write queries to answer each part separately
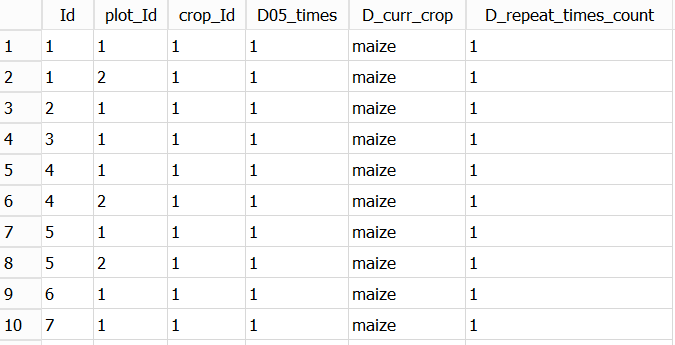
and
SQL
-- Which farms have more than 12 in the Household
SELECT Id, B_no_membrs
FROM Farms
WHERE B_no_membrs > 12
;In order to answer the question we need information from both tables
at the time, i.e. from a single query. Notice that in the tables
returned by both of the above queries we have the Id
column. This column represents the Household or Farm in both of the
tables. Because of this we can use this Id column from both
tables to JOIN the tables together.
Providing we are confident that both of the columns represent the household (or farm) it doesn’t matter whether or not they have the same name.
We write a JOIN query like this:
SQL
SELECT a.Id, a.B_no_membrs,
b.Id, b.D_curr_crop
FROM Farms AS a
JOIN Crops AS b
ON a.Id = b.Id AND a.B_no_membrs > 12 AND b.D_curr_crop = 'maize'
;There are several things to notice about this query:
- We have used alias’ for the table names in the same way as we used with columns in a previous lesson. In this case though, it is not to provide more meaningful names, in fact alias’ for tables are often single letters to save key strokes.
- We use the table alias as a prefix, plus a ‘.’ when we refer to a column name from the table. You don’t have to do this, but it generally adds clarity to the query.
- You will need to use an alias when you need to refer to a column
with the same name in both tables. In our case we need to compare the
Idcolumn in both tables. - In the select clause, we list all of the columns, from both table that we want in the output. We use the alias’ for clarity. If the column name is not ambiguous, i.e it only occurs in one of the tables it can be omitted, but as we have said it is better to leave it in for clarity.
- The name of the second table is given in the
JOINclause. - The conditions of the
JOINare given in theONclause. TheONclause is very much like aWHEREclause, in that you specific expressions which restrict what rows are output. In our example we have three expressions. The last two are the individual expressions we used in the previous, single table queries. The first expressiona.Id = b.Idis the expression which determines how we want the two tables to be joined. We are only interested in rows from both table where theIdvalues match.
When we run this query we get output like the following:
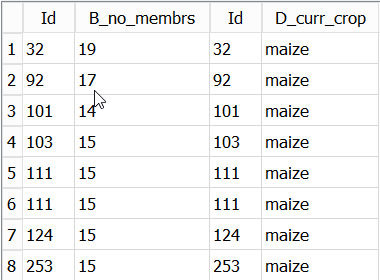
SQL
SELECT a.Id AS Farms_Id, a.B_no_membrs,
b.Id AS Crops_Id, b.plot_Id, b.D_curr_crop
FROM Farms AS a
JOIN Crops AS b
ON a.Id = b.Id AND a.B_no_membrs > 12 AND b.D_curr_crop = 'maize'
;- we can add alias’ to the two
Idcolumns to distinguish them. - by adding the
plot_Idcolumn from the Crops table. It is clear thatId111 has two plots (plot 1 and plot 2) growing maize.
Different join types
The example of a join given above is called an INNER join, we could have written INNER JOIN rather than simply JOIN. This is almost never done in practice as the inner join is by far the most common join type used.
Other Join types are available…
Before we look at the other join types we need to explain how the Inner join works and why it is so commonly used.
For any join (type) we are defining a relationship between two tables
based on the data values in two columns, one from each table. The
relationship is given by the criteria in the ON clause. The
value of the column in one table must be same as that in the other
table. That is; the criteria is given in the form
value_in_column_from_table_a = value_in_column_from_table_b.
Only if this criteria is TRUE will the requested columns from table_a
and table_b be returned as a single row in the output. During the join
process each row of the first with every row of the second and if a
match is found then a row combining the columns from both tables is
output.
Although typically the values being matched from the first table are a unique (Distinct) set of values, the values in the second table don’t have to be unique. This is why in the results of our previous query there are two entries with Id 111. In the second table there are two records with Id 111 and so the record from the first table gets combined with both the records in the second table and two records are output.
Because every Farm grows some crops, there will be at least one record for each Id output. I for whatever reason the was a Farm with no crops then there would be no record output for that Farm Id. Similarly if there was an entry in the Crops table with an Id which didn’t match any of the Ids in the Farms table, then it would not be output. There is only an output record when the two columns have matching values.
When a relational database is defined and the tables set up initially the relationship between the tables are already known, they are part of the design of the overall database. Because of this it is possible to ensure when the data is added to the tables that there will be entries in both tables which have matching values. At the very least you can prevent rows being added to the second table with a value in the column you intend to join on for which there is no matching column in the first table.
An inner join only returns rows where there is a match between the two columns. In most cases this will be all of the columns selected from the first table and 0,1 or more columns selected from the second table.
The relational design makes use of multiple tables as a way of avoiding repetition of data. Joining tables re-introduces the replication of the data.
There are several different join types possible
| Join Type | What it does |
|---|---|
| Inner Join | Matched rows in both tables are returned |
| Left outer join | All row in the left hand table are returned along with the matches from the right hand table or NULLs if there is no match |
| Right outer join | All row in the right hand table are returned along with the matches from the left hand table or NULLs if there is no match |
| Full outer join | All rows from both tables are returned, with NULLs where there are no matches |
| Cross join | Each row in the first table will be matched with every row in the second table. It is possible to imagine situations where this is required but in most cases it is a mistake and un-intended. |
In SQLite only the INNER JOIN, the
LEFT OUTER JOIN and the CROSS JOIN are
supported. You can create a Right outer join by swapping
the tables in the FROM and JOIN clauses. A
Full outer join is the combination of the Left outer and
Right outer joins.
Using different join types in analysing your data
In many cases the data you have in your tables may have come from disparate sources, in that they do not form part of a planned relational database. It has been your decision to bring together (join) the data in the tables.
In order to do this at all you must be confident that the tables of data do have columns which have a common set of values that you can join on.
Assuming you do have a common column to join on, you can use an
INNER JOIN to combine the data.
However it will also be important for you to establish rows in both of the tables for which there is no matching row in the other table.
- You may expect some to be missing
- You may not care that some are missing
- You may need to explain why some are missing
To do this you will want to use a FULL OUTER JOIN or in
the case of SQLite a LEFT OUTER JOIN run twice using both
tables in the FROM and JOIN clauses. We can
demonstrate ability LEFT OUTER JOIN using the Crops_rice
table we created earlier.
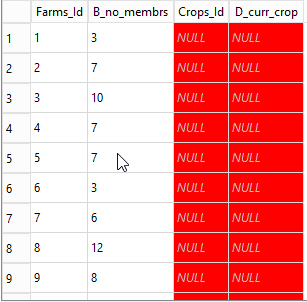
The query below is similar to our original join except that we are now joining with the crops_rice table and we have dropped the additional criteria.
SQL
SELECT a.Id AS Farms_Id, a.B_no_membrs,
b.Id AS Crops_Id, b.D_curr_crop
FROM Farms AS a
LEFT OUTER JOIN Crops_rice AS b
ON a.Id = b.IdYou can see from the results that there is an entry for every record in the Farms table, but unless there is a crop of rice, the entries in the columns from the crops_rice table are shown as NULL.
Joins with more than two tables
Joins are not restricted to just two tables. You can have any number, but the more you have the more unreadable the SQL query is likely to become. Quite often you can create views to hide this complexity.
Our original question was: ‘Which Farms with more than 12 people in
the household grow Maize?’ We found the number of people in the
household from the Farms table and the crops they grew in the crops
table. Suppose we now wanted to change the question to be: For Farms
with more than 12 people in the household how much land is devoted to
growing Maize? In addition to the previous requirements we now also need
the size of the plots growing maize. This information is only contained
in the plots table. The plots table has both
an Id column which we can use to join it with the Farms column. There is
also a plot_Id column which is used to indicate the number of the plot
within the Farm. The crops table also has a plot_id column
used for the same purpose.
However we cannot join the plots and the
crops table with just the plot_id column
because the plot_id column is not unique within the Plots
table. The plot_id is the plot number within a Farm. So
every Farm will have a plot_id with the value 1. In order to make what
we join on unique we need to use both the Id column and the plot_id
column together. This is allowed and quite commonly done.
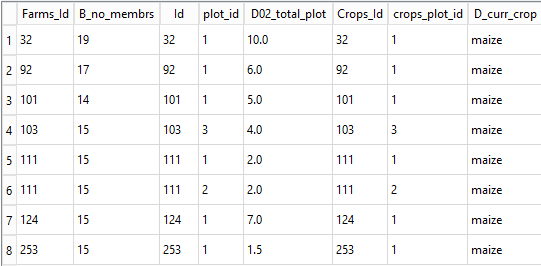
Our new query now looks like this:
SQL
SELECT a.Id AS Farms_Id, a.B_no_membrs,
b.Id , b.plot_id AS plot_id, b.D02_total_plot,
c.Id AS Crops_Id, c.plot_Id AS crops_plot_id, c.D_curr_crop
FROM Farms AS a
JOIN Plots AS b
JOIN Crops AS c
ON a.Id = b.Id AND (b.Id = c.Id AND b.plot_id = c.plot_id) AND a.B_no_membrs > 12 AND c.D_curr_crop = 'maize'
;Things to notice:
- There is a
JOINclause for each of the additional tables - But there is only one
ONclause containing all of the needed criteria. - The two criteria in brackets represents the join of the
plotstable to theCropstable. (The brackets aren’t needed, I just added them for clarity).
The results look like this:
Key Points
- Joins are used to combine data from two or more tables.
- Tables to be joined must have a column in each which represent the same thing
- There are several different types of joins
- The Inner join is the most commonly use
- You may have to use the other join types to discover missing data or gaps in your data
Content from Using database tables in other environments
Last updated on 2023-05-02 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- How do I save my query results for use by other programs or applications?
- What are and how do I use ODBC applications?
- How can I access an SQLite database table from other programming environments?
Objectives
- Understand what ODBC is and when it can be used
- Construct appropriate connection strings
- Appreciate the advantages of using ODBC to access a remote database
- Use an ODBC connection from Excel to retrieve data from a database
- Use ODBC from Python or other programming environment to retrieve data from a database
ODBC and advantages of using it
ODBC - Open Database Connectivity (or Connector) is a piece of
software, often referred to as a driver, which allows a
database to be connected to an application or program. ODBC drivers are
specific to a given database system. As we are using an
SQLite database we need an SQLite specific ODBC driver to
connect to it.
The installation of the SQLite ODBC driver for a Windows machine is explained in the SQL setup document .
So far in this lesson we have accessed our SQLite database either
through the DB Browser application or directly using the command line
shell. Each of these methods have their own advantages. The DB Browser
application provides a simple GUI (Graphical User Interface), for
development and testing new queries. The shell aids automation of tasks
such as adding rows to a table or allowing whole scripts of SQL commands
to be run consecutively without user intervention. In both of these
methods, we have seen that the ‘outputs’ can be saved to
csv files from where they can be read into other
applications or programs for futher processing. Using ODBC misses out
the middle man (the file of output). The application or program connects
directly to the SQLite database, sends it an SQL query, receives the
output from that query and processes the results in an appropriate
fashion.
In the case of Excel the tabular results of the query are displayed in a worksheet. For R and Python the results are assigned to a suitable variable from where they can be examined or further processed.
In the following sections we will give examples of using ODBC to connect to Excel and also accessing SQLite from R and Python programs.
Connection strings
A connection string is really just a list of parameters and their values which explain to the ODBC driver what database you wish to connect to and how you wish to use it. For some database systems this might involve providing user credentials as well as specifying which particular database you want to access. For our use of SQLite, the connection string is essentially the full pathname and filename of the SQLite database file.
How and where the connection string information is provided depends on the ODBC driver and the application or program being used.
Connecting to Excel using ODBC
Walkthrough example
- Open an empty Excel workbook
- From the Data ribbon select Get Data | From other Sources | From Microsoft Query
- From the Choose Data Source window select
SQLite3 Datasourceand click OK.
If this option does not appear in the list, then it probably means that the SQLite ODBC driver has not been installed.
The ‘Connect’ window is where you specify the connection string information. You can see that there are many things that can be specified. But all we need to specify is the Database name i.e. the full path and name of the database file. There is a browse button you can use to navigate to the required file. When you have selected the database file click OK
At this point, you may get an a window pop up saying that there are no tables
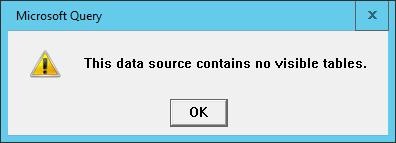
Click OK . The Choose Columns Windows appears to support the ‘no tables’ assertion.
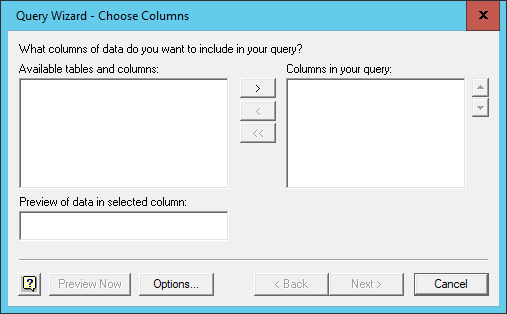
Click on the options button and then toggle the
system tables option and click OK,
then the tables will appear.
(There is no technical reason why the above procedure to see the tables should be necessary, it appears to be a fault in the ODBC driver, which fortunately we can work around.)
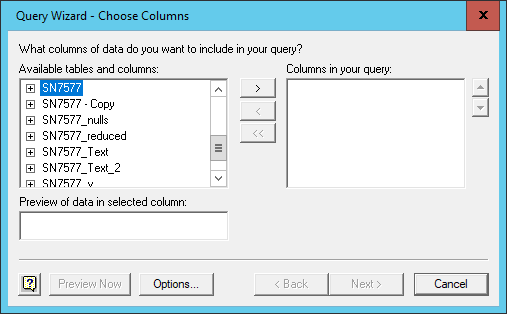
Select the Farms table and then click the ‘>’ button to select all
of the columns from the Farms table. They will be displayed in the right
hand pane. This is the equivalent of the SELECT * SQL
clause that we have used before. If you click the ‘+’ button to the left
of the table name, a full list of the column names is displayed allowing
you to select individual columns for inclusion. Click
Next
- Subsequent windows allow you to filter the rows returned, this is
equivalent to adding a
WHEREclause to the query and finally you can have the returned rows sorted, equivalent to aSORT BYclause. We shall just default these options. The final window asks us if we want to return the data to Excel or further edit the query we have built up using Microsoft query. We will leave the default action of rturning the data to Excel. Click Finish
The overall effect of this wizard is to construct an SQL query, in
this case SELECT * FROM Farms send it to the SQLite system
to be run and then to recieve back the results.
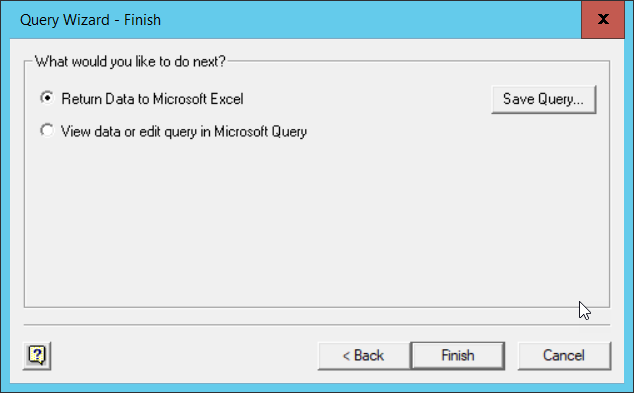
- Although the wizard has finished we still need to say where we want the data placed in our workbook. We will accept the default position of the ‘A1’ cell in the current workbook.
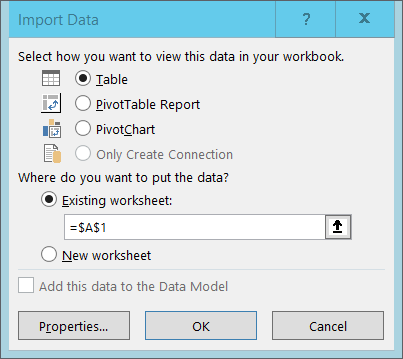
The data is returned as an Excel Table. All of the
columns have their headings included and have filter buttons attached.
You can now manipulate the data in Excel as you would any other
data.
Connecting to Python or other programming environments using ODBC
Both Python and R (and many other programming languages) provide methods of connecting to and extracting data from SQLite databases. Full details and examples are provided in the Python lesson and the R lesson.
For now we will just look at code examples in Python and R, both of which run the same query as we used for the Excel example above.
R
R
library("RSQLite")
dbfile = "C:/Users/pfsmy/OneDrive/UoM/Carpentry/Datasets/SN7577.sqlite"
sqlite = dbDriver("SQLite")
mydb = dbConnect(sqlite, dbfile)
results = dbSendQuery(mydb, "SELECT * FROM SN7577")
data = fetch(results)
data
dbClearResult(results)
We will not discuss the working of the code, that is covered in the Python and R lessons. Even without coding experience of these languages, you will be able to spot that in both cases we need to specify a connection string (the SQLite database filename) and also the text of the query itself.
In both cases the results are stored in a variable object of the language.
Key Points
- ODBC - Open DataBase Connector allows a database to be connected to a program or application
- Each database system has its own ODBC connectors
- Programs such as Excel allow you to use ODBC to get data from databases
- Programming languages such as Python and R provide libraries which facilitate ODBC connections