Learning Objectives
Following this assignment students should be able to:
- install and load an R package
- understand the data manipulation functions of
dplyr- execute a simple import and analyze data scenario
Reading
Readings
Optional Resources:
Lecture Notes
Place this code at the start of the assignment to load all the required packages.
library(dplyr)
Exercises
Shrub Volume Data Basics (20 pts)
Dr. Morales is interested in studying the factors controlling the size and carbon storage of shrubs. She has conducted an experiment looking at the effect of three different treatments on shrub volume at four different locations. She has placed the data file on the web for you to download:
If the file
shrub-volume-data.csvis not already in your working directory (it probably is if you’re taking this class using Posit Cloud) then download it into your working directory.Get familiar with the data by importing it using
read.csv()and usedplyrto complete the following tasks.- Select the data from the length column (using
select). - Select the data from the site and experiment columns (using
select). - Add a new column named
areacontaining the area of the shrub, which is the length times the width (usingmutate). - Sort the data by length (using
arrange). - Filter the data to include only plants with heights greater than 5 (using
filter). - Filter the data to include only plants with heights greater than 4 and widths greater than 2 (using
,or&to include two conditions). - Filter the data to include only plants from Experiment 1 or Experiment 3 (using
|for “or”). - Filter the data to remove rows with null values in the
heightcolumn (using!is.na) - Create a new data frame called
shrub_volumesthat includes all of the original data and a new column containing the volumes (length * width * height), and display it.
- Select the data from the length column (using
Code Shuffle (20 pts)
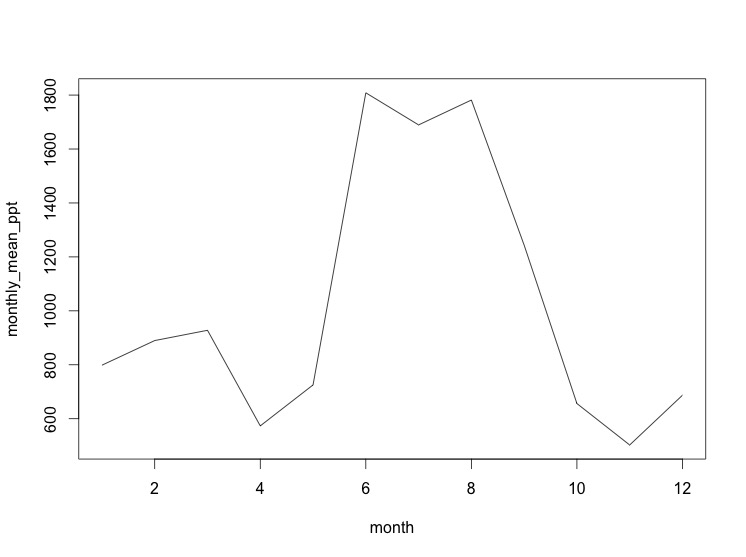
We are interested in understanding the monthly variation in precipitation in Gainesville, FL. We’ll use some data from the NOAA National Climatic Data Center. Each row of the data is a year (from 1961-2013) and each column is a month (January - December).
Rearrange the following program so that it:
- Imports the data from the web into a data frame
- Calculates the mean precipitation (ppt) in each month across years
- Plots the monthly averages as a simple line plot
Finally, add a comment above the code that describes what it does. The comment character in R is
#.It’s OK if you don’t know exactly how the details of the program work at this point, you just need to figure out the right order of the lines based on when variables are defined and when they are used.
Expected outputs for Code Shuffle: 1plot(monthly_mean_ppt, type = "l", xlab = "Month", ylab = "Mean Precipitation") monthly_mean_ppt <- colMeans(ppt_data) ppt_data <- read.csv("https://datacarpentry.org/semester-biology/data/gainesville-precip.csv", header = FALSE)Bird Banding (20 pts)
The number of birds banded at a series of sampling sites has been counted by your field crew and entered into the following vector. Counts are entered in order and sites are numbered starting at one. Cut and paste the vector into your assignment and then answer the following questions by using code and printing the result to the screen. Some R functions that will come in handy include
length(),max(),min(),sum(), andmean().number_of_birds <- c(28, 32, 1, 0, 10, 22, 30, 19, 145, 27, 36, 25, 9, 38, 21, 12, 122, 87, 36, 3, 0, 5, 55, 62, 98, 32, 900, 33, 14, 39, 56, 81, 29, 38, 1, 0, 143, 37, 98, 77, 92, 83, 34, 98, 40, 45, 51, 17, 22, 37, 48, 38, 91, 73, 54, 46, 102, 273, 600, 10, 11)- How many sites are there?
- How many birds were counted at site 42?
- What is the total number of birds counted across all of the sites?
- What is the smallest number of birds counted?
- What is the largest number of birds counted?
- What is the average number of birds seen at a site?
- How many birds were counted at the last site? Have the computer choose the last site automatically in some way, not by manually entering its position. Do you know a function that will give you the position of the last value? (since positions start at 1 the position of the last value in a vector is the same as its length).
Portal Data Manipulation (20 pts)
If the file
surveys.csvis not already in your working directory then download a copy.Load the file into R using
read.csv().Do not use pipes for this exercise.
- Use
select()to create a new data frame with just theyear,month,day, andspecies_idcolumns in that order. - Use
mutate(),select(), andfilter()with!is.na()to create a new data frame with theyear,species_id, and weight in kilograms of each individual, with no null weights. The weight in the table is given in grams so you will need to create a new column for weight in kilograms by dividing the weight column by 1000. - Use the
filter()function to get all of the rows in the data frame for the species IDSH.
- Use
Portal Data Manipulation Pipes (20 pts)
If the file
surveys.csvis not already in your working directory then download a copy.Load the file into R using
read.csv().Use pipes (either
|>or%>%) to combine the following operations to manipulate the data.- Use
mutate(),select(), andfilter()withis.na()to create a new data frame with theyear,species_id, and weight in kilograms of each individual, with no null weights. - Use the
filter()andselect()to get theyear,month,day, andspecies_idcolumns for all of the rows in the data frame wherespecies_idisSH.
- Use
Portal Data Challenge (optional)
If the file
surveys.csvis not already in your working directory then download a copy.Develop a data manipulation pipeline for the Portal
Expected outputs for Portal Data Challenge: 1surveystable that produces a table of data for only the three Dipodomys species (DM,DO,DS). The species IDs should be presented as lower case, not upper case. The table should contain information on the date, the species ID, the weight and hindfoot length. The data should not include null values for either weight or hindfoot length. The table should be sorted first by the species (so that each species is grouped together) and then by weight, with the largest weights at the top.
{kind=link}