Using scripts
Last updated on 2023-06-12 | Edit this page
Estimated time: 20 minutes
Overview
Questions
- How can we document the data-cleaning steps we’ve applied to our data?
- How can we apply these steps to additional data sets?
Objectives
- Describe how OpenRefine generates JSON code representing the work done in an analysis session.
- Demonstrate ability to export this JSON code from OpenRefine.
- Demonstrate ability to import a JSON code file to apply the analysis to another dataset.
How OpenRefine records what you have done
As you conduct your data cleaning and preliminary analysis, OpenRefine saves every change you make to the dataset. These changes are saved in a format known as JSON (JavaScript Object Notation). You can export this JSON script and apply it to other data files. If you had 20 files to clean, and they all had the same type of errors (e.g. misspellings, leading white spaces), and all files had the same column names, you could save the JSON script, open a new file to clean in OpenRefine, paste in the script and run it. This gives you a quick way to clean all of your related data.
Saving your work as a script
- In the
Undo / Redosection, clickExtract..., and select the steps that you want to apply to other datasets by clicking the check boxes.
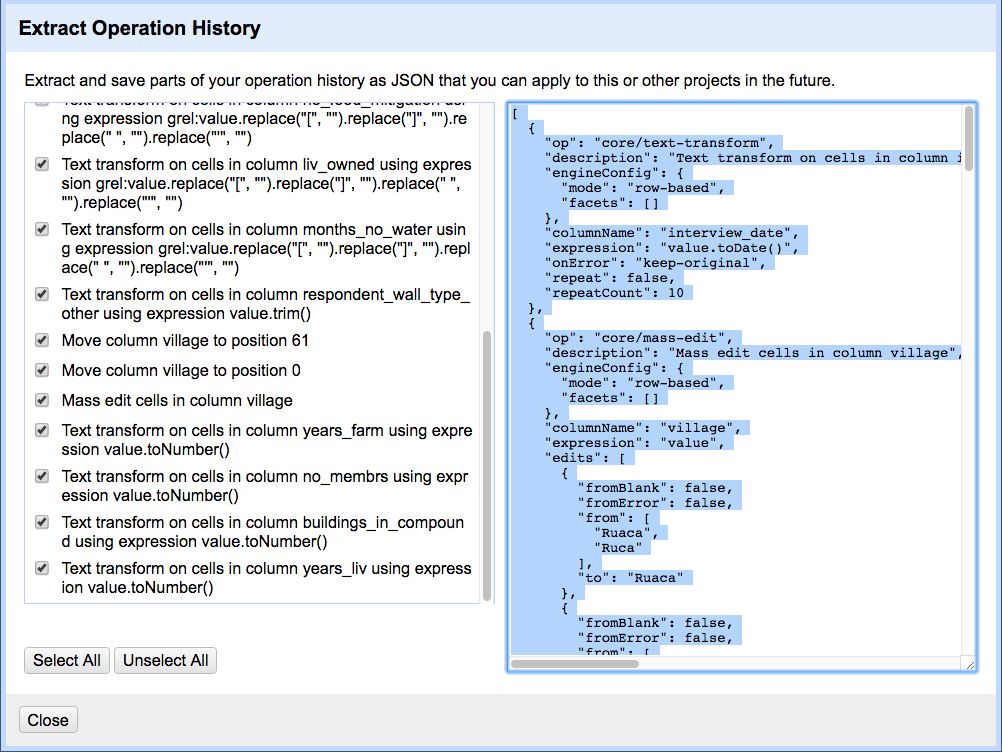
- Copy the code from the right hand panel and paste it into a text
editor (like NotePad on Windows or TextEdit on Mac). Make sure it saves
as a plain text file. In TextEdit, do this by selecting
Format>Make plain textand save the file as a.txtfile.
Importing a script to use against another dataset
Let’s practice running these steps on a new dataset. We’ll test this on an uncleaned version of the dataset we’ve been working with.
- Start a new project in OpenRefine using the messy dataset you downloaded before. Give the project a new name.
- Click the
Undo / Redotab >Applyand paste in the contents of.txtfile with the JSON code. - Click
Perform operations. The dataset should now be the same as your other cleaned dataset.
For convenience, we used the same dataset. In reality you could use this process to clean related datasets. For example, data that you had collected over different fieldwork periods or data that was collected by different researchers (provided everyone uses the same column headings). The data in this file was generated from an eSurvey system with the actual survey being delivered centrally to a smartphone, so the column headings are pretty much guaranteed to be the same.
Key Points
- All changes are being tracked in OpenRefine, and this information can be used for scripts for future analyses or reproducing an analysis.