Combine Data
Overview
Teaching: 0 min
Exercises: 0 minQuestions
How do I combine data from different files?
Objectives
Merge two different datasets using unique keys.
The commands append and merge combine a dataset in memory (the “master” data) to another one on disk (the “using” data). append adds more observations, merge adds more variables by matching keys between the two datasets.

Data in memory, data on disk
Stata is different from other popular statistical and data manipulation languages like R (Data Frame) and Python (Pandas) in that it can only hold one dataset in memory at a time. In most applications, you will work with multiple datasets, so you will need to
mergethem quite often. Stata 16 allows for multiple data frames in memory.
The command append is used to combine datasets with the same columns, each representing a different set of observations. A common use case is combining large datasets broken into smaller chunks.
Load GDP data from the annual files data/derived/gdp1990.dta, data/derived/gdp1991.dta, etc.
use "data/derived/gdp1990.dta", clear
describe
append using "data/derived/gdp1991.dta"
describe
. use "data/derived/gdp1990.dta", clear
. describe
Contains data from data/derived/gdp1990.dta
obs: 264
vars: 2 22 Aug 2019 13:39
size: 2,904
--------------------------------------------------------------------------------------
storage display value
variable name type format label variable label
--------------------------------------------------------------------------------------
countrycode str3 %9s Country Code
gdp_per_capita double %8.0g gdp_per_capita v
--------------------------------------------------------------------------------------
Sorted by: countrycode
. append using "data/derived/gdp1991.dta"
. describe
Contains data from data/derived/gdp1990.dta
obs: 528
vars: 2 22 Aug 2019 13:39
size: 5,808
--------------------------------------------------------------------------------------
storage display value
variable name type format label variable label
--------------------------------------------------------------------------------------
countrycode str3 %9s Country Code
gdp_per_capita double %8.0g gdp_per_capita v
--------------------------------------------------------------------------------------
Sorted by:
Note: Dataset has changed since last saved.
Note that the files does not contain a year variable, so we would not know which observation is coming from which year. We modify the code to create a variable called year.
use "data/derived/gdp1990.dta", clear
generate year = 1990
append using "data/derived/gdp1991.dta"
Looking at the data, we see that variables that have the same name are combined as expected.
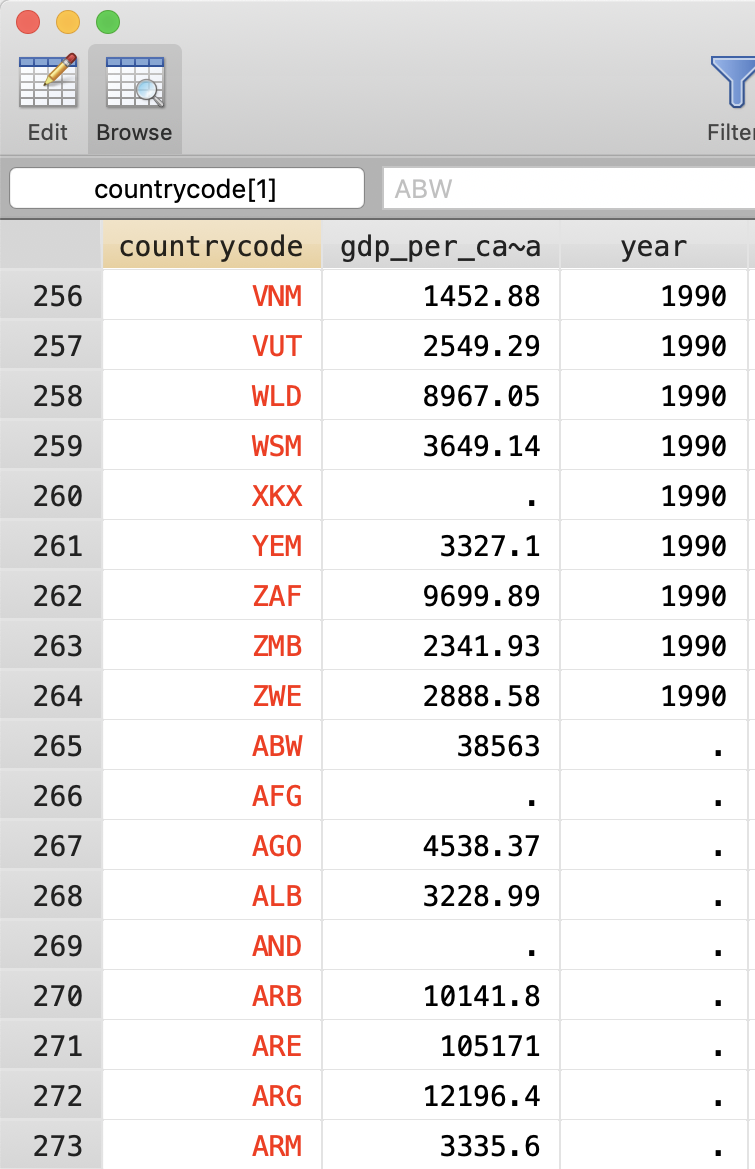
We can also see the edge of the two datasets: the master data ends with “Zimbabwe,” the using data starts with “Aruba.” (Usually this will not be as obvious.)
Because the variable year was not defined in gdp1991.dta, its values are missing for observations that comes from this file. This suggest that we can update the year based on missing values. Our final combination code will look like this.
use "data/derived/gdp1990.dta", clear
generate year = 1990
append using "data/derived/gdp1991.dta"
replace year = 1991 if missing(year)
append using "data/derived/gdp1992.dta"
replace year = 1992 if missing(year)
...
All this repetition of years makes our code prone to errors. We will automate this process in Episode 6
Merge
Load the decadal WDI data. Merge the average distance measure for each country.
use "data/wdi_decades.dta", clear
merge m:1 countrycode using "data/average_distance.dta"
variable countrycode not found
r(111);
The problem is that in the “using” dataset (data/average_distance.dta), country codes are called iso_o, not countrycode. Merge requires that the keys on which you are merging are called the same in both datasets.
use "data/wdi_decades.dta", clear
rename countrycode iso_o
merge m:1 iso_o using "data/average_distance.dta"
Result # of obs.
-----------------------------------------
not matched 220
from master 195 (_merge==1)
from using 25 (_merge==2)
matched 597 (_merge==3)
-----------------------------------------
. tabulate _merge
_merge | Freq. Percent Cum.
------------------------+-----------------------------------
master only (1) | 195 23.87 23.87
using only (2) | 25 3.06 26.93
matched (3) | 597 73.07 100.00
------------------------+-----------------------------------
Total | 817 100.00
By default, each row gets a merge code, saved in a new variable called _merge. Merge codes are useful to check the results of our merge. “Master” is the dataset in memory, “using” is the dataset on disk.
. use "data/wdi_decades.dta", clear
. rename countrycode iso_o
. merge m:1 iso_o using "data/average_distance.dta", keep(master match)
Result # of obs.
-----------------------------------------
not matched 195
from master 195 (_merge==1)
from using 0 (_merge==2)
matched 597 (_merge==3)
-----------------------------------------
. tabulate _merge
_merge | Freq. Percent Cum.
------------------------+-----------------------------------
master only (1) | 195 24.62 24.62
matched (3) | 597 75.38 100.00
------------------------+-----------------------------------
Total | 792 100.00
Since merge displays the distribution of merge codes, we often do not need to save it directly. merge m:1 iso_o using "data/average_distance.dta", keep(master match) nogenerate. As many Stata commands, merge allows several options to be combined.
One to many, many to one
We have seen a many-to-one
m:1merge, where the “master” data has many rows with the same key, the “using” data has only one row for each key value. One-to-many1:mare exactly the flipside of this, with the role of “master” and “using” data reversed.
Challenge
Use “data/average_distance.dta” and merge the data with “data/gdp2017.dta”
Solution
. use "data/average_distance.dta", clear rename iso_o countrycode merge 1:1 countrycode using "data/gdp2017.dta", keep(match) nogenerateNote the missing values. There are eight countries dropped in total.
Gotcha
Never do a many-to-many,
m:mmerge. It does not do what you expect. You probably want to do ajoinbyinstead.
Key Points
Create tidy data before merging.