Read and Explore Data
Overview
Teaching: 40 min
Exercises: 10 minQuestions
How can I explore my data?
How does Stata deal with variable names it doesn’t like?
Objectives
Determine and change your working directory in Stata.
Read and write data using relative path.
Explore your dataset using
browse,describe,summarize,tabulateandinspect.
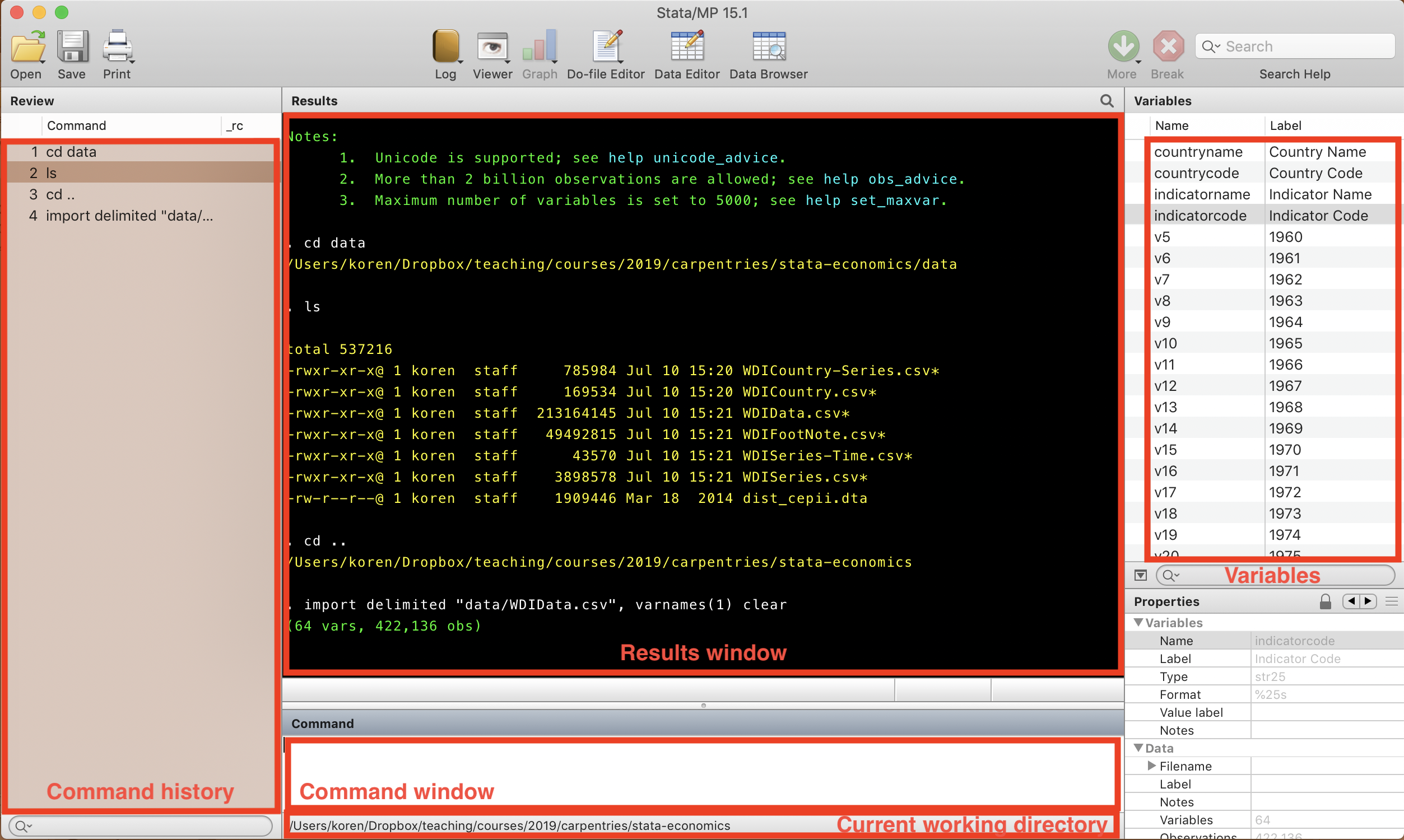
Stata screenshots are used with the permission of StataCorp LLC to use in this and derived instructional materials. All other rights reserved.
How do you find your current working directory? Check the bottom line of the Stata application window, or enter the command pwd.
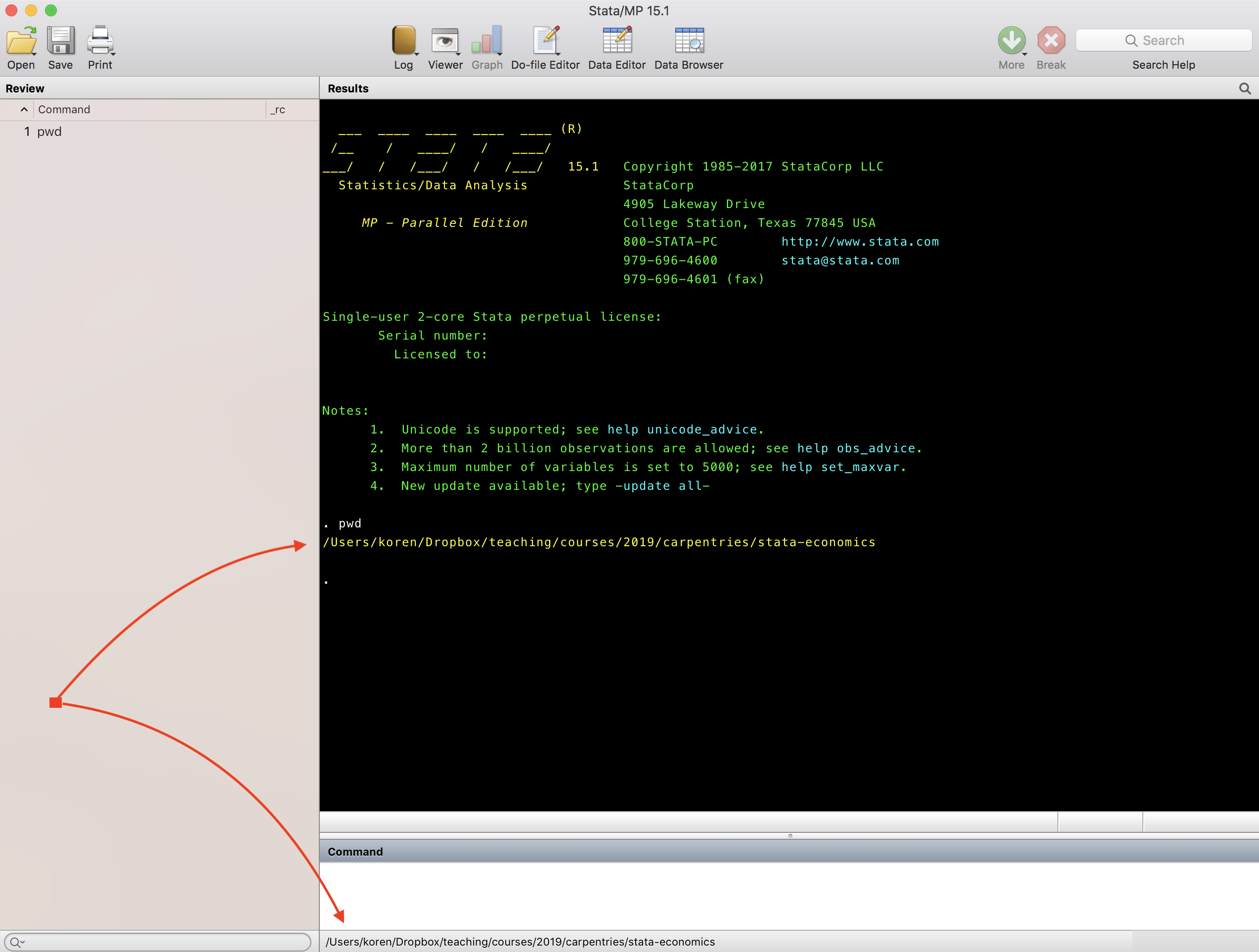
When you use the command window Stata shows the outputs in the results window. The display command in Stata, which is similar than print command in other programming languages, could displays strings, values or produces outputs from the programs that you write.
. display "Hello world!"
Hello world!
Interactively display can be used as a substitute for a hand calculator.
. display 2*2
4
Backward or forward?
On a Windows machine, Stata will display your working directory with a backslash (
\) separating its components, likeC:\Users\koren\Dropbox\teaching\courses\2019\carpentries\stata-economics. Refer to directories using a forward slash (/) to stay compatible with other platforms. The forward slash is understood by all three major platforms, whereas the backslash has a special meaning on Unix and Mac.
cd data
/Users/koren/Dropbox/teaching/courses/2019/carpentries/stata-economics/data
ls
total 537216
-rwxr-xr-x@ 1 koren staff 785984 Jul 10 15:20 WDICountry-Series.csv*
-rwxr-xr-x@ 1 koren staff 169534 Jul 10 15:20 WDICountry.csv*
-rwxr-xr-x@ 1 koren staff 213164145 Jul 10 15:21 WDIData.csv*
-rwxr-xr-x@ 1 koren staff 49492815 Jul 10 15:21 WDIFootNote.csv*
-rwxr-xr-x@ 1 koren staff 43570 Jul 10 15:21 WDISeries-Time.csv*
-rwxr-xr-x@ 1 koren staff 3898578 Jul 10 15:21 WDISeries.csv*
-rw-r--r--@ 1 koren staff 1909446 Mar 18 2014 dist_cepii.dta
Note this will look different on a Windows machine.
cd ..
/Users/koren/Dropbox/teaching/courses/2019/carpentries/stata-economics
Everything we do pointing and clicking leaves a trace in the command line. This will help us write reproducible code later.
use "/Users/koren/Dropbox/teaching/courses/2019/carpentries/stata-economics/data/raw/cepii/dist_cepii.dta"
Challenge
If your current working directory is
/home/user/stata-economics, which of the following can you use to load the data in/home/user/stata-economics/data/raw/cepii/dist_cepii.dta?
use "/home/user/stata-economics/data/raw/cepii/dist_cepii.dta"use "data/raw/cepii/dist_cepii.dta"use "/data/raw/cepii/dist_cepii.dta"use "data\raw\cepii\dist_cepii.dta"use "../dist_cepii.dta"Solution
Variables
Let us look at our data first. This is the first thing to do after loading a new Stata dataset.
browse
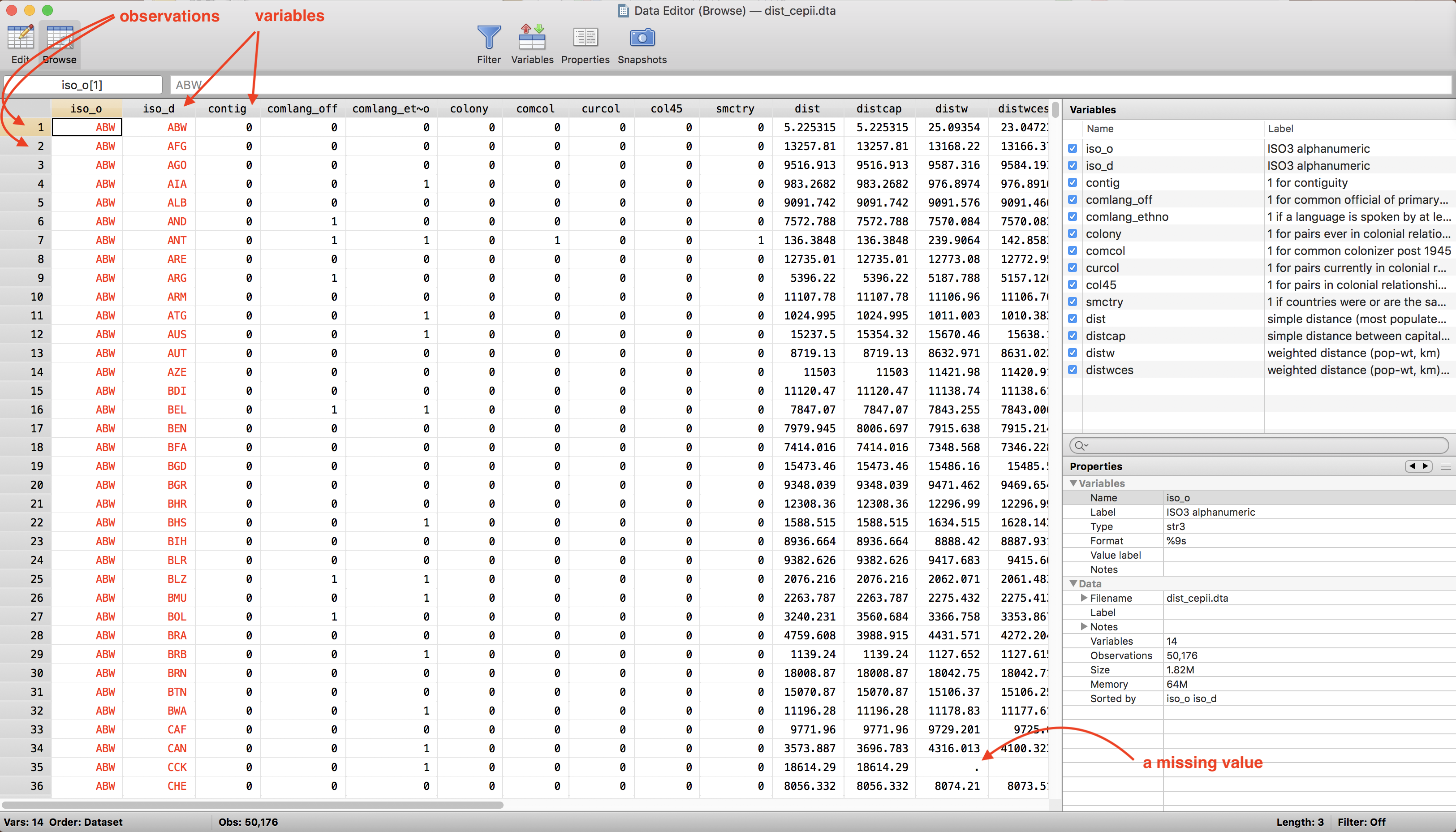
Stata datasets are a table of “variables” and “observations.” Variables have names with which we can refer to them. Observations are rows of the table, with values for each variable. Red values in the browser are strings. We also see that Stata uses . for denoting missing values.
What do these variables mean? Can we use more verbose names for them?
. describe
Contains data from /stata-economics/data/raw/cepii/dist_cepii.dta
obs: 50,176
vars: 14 8 Oct 2004 20:08
size: 1,906,688
---------------------------------------------------------------------------------------------
storage display value
variable name type format label variable label
---------------------------------------------------------------------------------------------
iso_o str3 %9s ISO3 alphanumeric
iso_d str3 %9s ISO3 alphanumeric
contig byte %8.0g 1 for contiguity
comlang_off byte %8.0g 1 for common official of primary language
comlang_ethno byte %8.0g 1 if a language is spoken by at least 9% of the
population in both countries
colony byte %8.0g 1 for pairs ever in colonial relationship
comcol byte %8.0g 1 for common colonizer post 1945
curcol byte %8.0g 1 for pairs currently in colonial relationship
col45 byte %8.0g 1 for pairs in colonial relationship post 1945
smctry byte %9.0g 1 if countries were or are the same country
dist float %9.0g simple distance (most populated cities, km)
distcap float %9.0g simple distance between capitals (capitals, km)
distw double %9.0g weighted distance (pop-wt, km)
distwces double %9.0g weighted distance (pop-wt, km) CES distances
with theta=-1
---------------------------------------------------------------------------------------------
Sorted by: iso_o iso_d
Can we give a more verbose name to iso_o?
. rename iso_o iso_3166_alphanumeric_origin_country
1 new variable name invalid
You attempted to rename iso_o to iso_3166_alphanumeric_origin_country. That is an
invalid Stata variable name.
r(198);
Variable names
Good variable names are short and descriptive. In Stata, variable names can include letters, digits, and underscores but they cannot start with a digit and are case sensitive. Variables can be at most 32 characters in length.
Variables are generated with the generate command and are assigned a value using =.
generate missing_distw = 1
You can replace the values of an existing variable using command replace.
replace missing_distw = 0
Since Stata 14, you can use Unicode variable names, but please be gentle: your coauthors may not have the keyboard to type these names.
generate távolság = dist
Stata allows you to abbreviate the name of a variable to the shortest string of characters that uniquely identifies it.
. describe comlang
comlang ambiguous abbreviation
r(111);
The error occurs because two variables have the same abbreviation, comlang, in common. If you instead ask Stata to do the following
. describe comlang_o
storage display value
variable name type format label variable label
----------------------------------------------------------------------------------------------
comlang_off byte %8.0g 1 for common official of primary language
Stata will describe the variable. If you would like to know if variables in your dataset have a common abbreviation, you can use wildcards.
For example, you could refer to all variables that start with dist by using wildcard pattern: * that matches zero or more characters or ? that matches exactly one character.
describe dist*
storage display value
variable name type format label variable label
----------------------------------------------------------------------------------------------
dist float %9.0g simple distance (most populated cities, km)
distcap float %9.0g simple distance between capitals (capitals, km)
distw double %9.0g weighted distance (pop-wt, km)
distwces double %9.0g weighted distance (pop-wt, km) CES distances
with theta=-1
. describe dist?
storage display value
variable name type format label variable label
----------------------------------------------------------------------------------------------
distw double %9.0g weighted distance (pop-wt, km)
.
When displaying long variable names, some Stata commands will abbreviate the variable name using ~, making it hard to understand what variables we are dealing with.
. summarize comlang_ethno
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
comlang_et~o | 50,176 .1691645 .3749009 0 1
To avoid using long variable names, you can shorten them and provide a more detailed description about the variable using variable labels. Labels help your coauthors, including your future self, make sense of what is in the variable. For example, that is how we learn that distance is measured in kilometers, not miles. Always use them.
Never abbreviate
A quirky feature of Stata is that it lets you abbreviate everything: commands, variable names, even file names. Abbreviation might save you some typing, but destroys legibility of your code, so please think of your coauthors and your future self and never do it.
u data, clear g gdp_per_capita = 1 ren gdp gdpmeans the same as
use "data.dta", clear generate gdp_per_capita = 1 rename gdp_per_capita gdpbut the latter is much more explicit. The built-in editor of Stata 16 offers tab completion so you don’t even have to type to write out the full command and variable names.
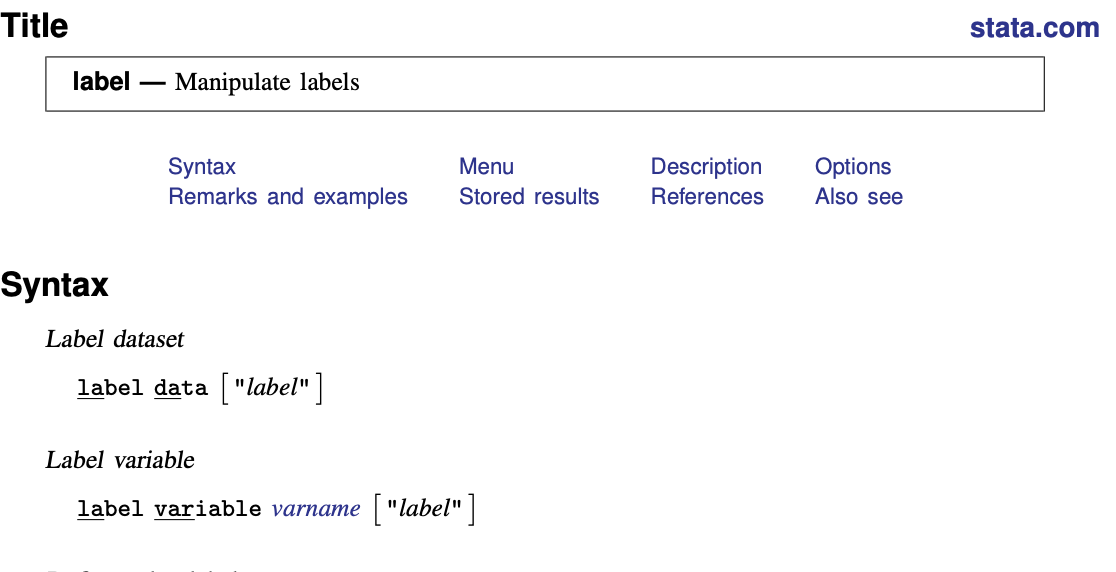
. label variable iso_o "ISO3166 alphanumeric code of origin country"
. describe iso_o
storage display value
variable name type format label variable label
---------------------------------------------------------------------------------------------
iso_o str3 %9s ISO3166 alphanumeric code of origin country
If you don’t know or recall a command in Stata, searching the Internet will almost always turn out useful. For example, if you search label variables Stata, the fist link that will show up is the official Stata Manual.
Command syntax
The summarize command displays summary statistics about a variable.
. summarize dist
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
dist | 50,176 8481.799 4703.571 .9951369 19951.16
We can add options with a comma. For example, here is the option detail.
. summarize dist, detail
simple distance (most populated cities, km)
-------------------------------------------------------------
Percentiles Smallest
1% 381.8563 .9951369
5% 1366.76 1.189416
10% 2263.26 1.407336 Obs 50,176
25% 4783.271 1.723628 Sum of Wgt. 50,176
50% 8084.515 Mean 8481.799
Largest Std. Dev. 4703.571
75% 12030.18 19904.45
90% 15276.66 19904.45 Variance 2.21e+07
95% 16714.46 19951.16 Skewness .25614
99% 18569.45 19951.16 Kurtosis 2.191578
Note that here, because we have more space, the label of the variable is used, not its short name.
(Almost) every command can be run on a subset of observations, selected by an if condition. An if condition consists of the word if followed by some condition that is either true or false.
. summarize dist if dist < 1000, detail
simple distance (most populated cities, km)
-------------------------------------------------------------
Percentiles Smallest
1% 5.826925 .9951369
5% 60.77057 1.189416
10% 131.0087 1.407336 Obs 1,644
25% 320.5764 1.723628 Sum of Wgt. 1,644
50% 595.3761 Mean 563.3924
Largest Std. Dev. 294.0478
75% 816.7297 998.694
90% 932.9859 998.694 Variance 86464.13
95% 969.2816 999.9088 Skewness -.2782705
99% 996.0536 999.9088 Kurtosis 1.856825
Note that fewer observations are included because of the if condition. Also, as we would expect, all distances are less than 1,000km.
The if condition can refer to any function of any other variable, even those that are not used in the command. Here we are summarizing distance for country pairs that are contiguous (share a common border). Note that both the mean and the median distance are much smaller.
. summarize dist if contig == 1, detail
simple distance (most populated cities, km)
-------------------------------------------------------------
Percentiles Smallest
1% 85.94135 10.47888
5% 172.7219 10.47888
10% 215.0746 59.61723 Obs 616
25% 417.8577 59.61723 Sum of Wgt. 616
50% 789.7066 Mean 1090.698
Largest Std. Dev. 1004.337
75% 1357.383 5795.045
90% 2380.92 5795.045 Variance 1008693
95% 3277.169 6418.446 Skewness 2.030284
99% 4464.312 6418.446 Kurtosis 8.019088
The operator == tests for equality.
You really can use any function after if. This is an easy way to do something on a sample for big datasets:
. summarize dist
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
dist | 50,176 8481.799 4703.571 .9951369 19951.16
. set seed 17082019
. summarize dist if uniform() < 0.10
Variable | Obs Mean Std. Dev. Min Max
-------------+---------------------------------------------------------
dist | 5,006 8420.376 4743.775 .9951369 19710.32
The function uniform() returns uniform random numbers between 0 and 1, so the above takes a 10 percent random sample from our observations.
Set the seed in order to get the same sample and results every time. If you do not set the seed, Stata will start its algorithm with the seed 123456789.
The inspect command displays a different type of summary than summarize command provided. Relevant only for numeric variables.
inspect dist
dist: simple distance Number of Observations
Total Integers Nonintegers
# Negative - - -
# # Zero - - -
# # # Positive 50,176 26 50,150
# # # # ----------- ----------- ----------
# # # # Total 50,176 26 50,150
# # # # # Missing -
+---------------------- -----------
.9951369 19951.16 50,176
(More than 99 unique values)
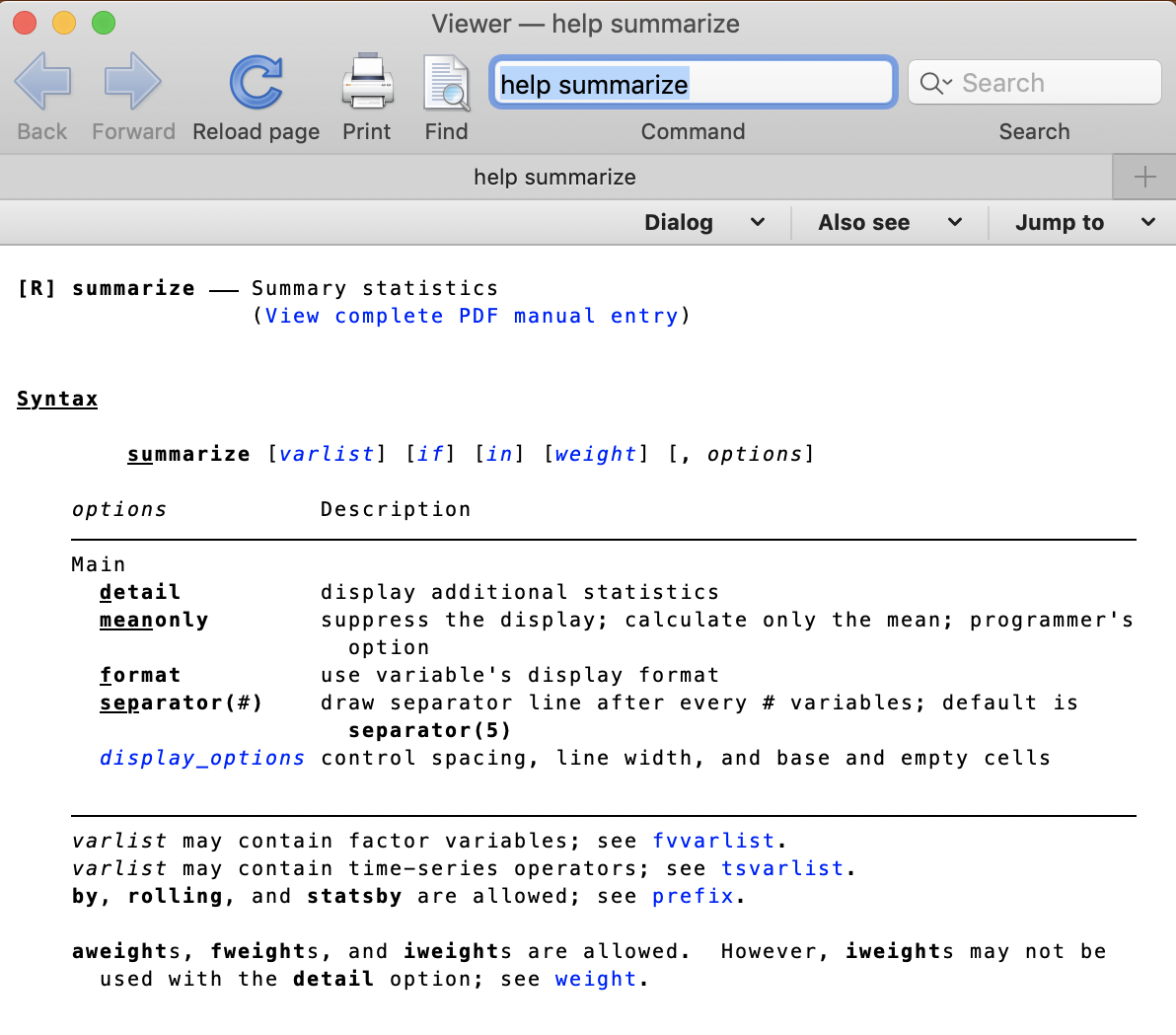
You can reach the Stata built in manuals if you write help and the name of the command into the command line.
help summarize
In the help documentation you can find syntax details, descriptions, links, options and examples.
Sometimes Stata documentation is of really high quality. It gives plenty of examples and often includes the precise formula a given command is using.
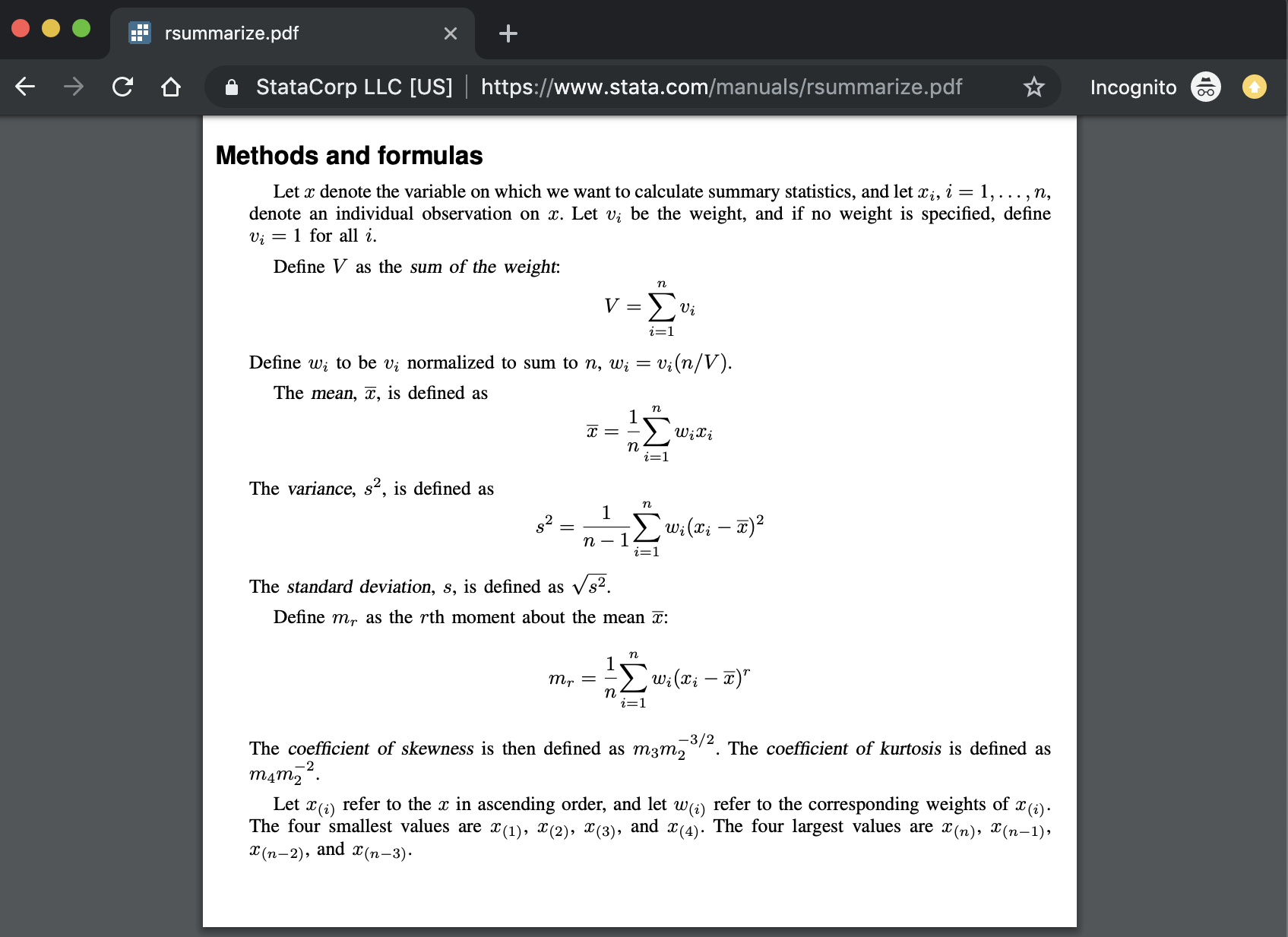
Challenge
Load
data/raw/cepii/dist_cepii.dta. Explore the variabledistw(weighted average distance between cities in the pair of countries).
- What is the unit of measurement?
- What is the smallest and largest value?
- In how many cases is this variable missing?
Solution
Challenge
Load
data/raw/cepii/dist_cepii.dta. Do you usecodebookorinspectto check how many distinct countries are coded iniso_d?Solution
Key Points
Always write out filename extensions to avoid confusion.
Always use forward slash
/in path names.Use short and descriptive variable names.
Label your variables.