Summary and Setup
This is an alpha lesson to teach Data Management with SQL for Social Scientists, We welcome and criticism, or error; and will take your feedback into account to improve both the presentation and the content.
This lesson is not currently under active maintenance. You are welcome to teach the lesson and contribute changes to the content, but you may have to wait longer than usual for any contributions to be processed. If you are interested in volunteering as a Maintainer on this lesson, please contact The Carpentries Curriculum Team or open an issue in this repository.
Databases are useful for both storing and using data effectively. Using a relational database serves several purposes.
- It keeps your data separate from your analysis. This means there’s no risk of accidentally changing data when you analyze it.
- If we get new data we can rerun a query to find all the data that meets certain criteria.
- It’s fast, even for large amounts of data.
- It improves quality control of data entry (type constraints and use of forms in Access, Filemaker, etc.)
- The concepts of relational database querying are core to understanding how to do similar things using programming languages such as R or Python.
This lesson will teach you what relational databases are, how you can load data into them and how you can query databases to extract just the information that you need.
Prerequisites
We expect you to have learn a bit about the SAFI dataset in the spreadsheet and OpenRefine session. It is not necessary, but will greatly improve your ability to understand the power of SQL and when to use it versus another tool.
Download files
You will need these two files:
- Pre-populated SQLite database: SQL_SAFI.sqlite
- SAFI Farms table as a CSV file: SAFI_farms.csv
Installing DB Browser for SQLite
The software can be downloaded from the DB Browser site From the front page you can select the version you require. There are specific downloads for Windows and Mac users. For various Linux distributions there are detailed instructions at the bottom of the page.
Installing for Windows.
For a current Windows environment the 64-bit windows download will be most appropriate.
The download is a windows executable file which you can run by double clicking it. It opens an installation wizard. You can default all of the options in the wizard. You will require admin permissions on the PC/Laptop you install on. By default the application is launched automatically when the installation is complete. It does not create an icon on the desktop. To explicitly launch the application after installing it, use the windows button (bottom left of screen) and type in ‘DB Browser’ in the search bar and selecting the application when it appears.
Install the SQLite Shell program
The SQLite shell can be downloaded from here. There are versions available for Linux, Mac and Windows. As I have a Windows machine I will download the Windows version. You should download the version appropriate to your machine. Note that MacOS already have sqlite installed so you can skip this section.

The number after the x86- may be different when you download if a later version has been released. The download is a .zip file. You need to unzip the file and store the contents (3 files) in a folder of your choosing. There is no actual install process, the program (file) sqlite3.exe can be run directly from the folder. You may however like to add the folder location to your PATH environment variable so that you can call sqlite3 from any command prompt.
Invoke the SQLite Shell program
You invoke the SQLite Shell from the commandline. Remember that the program is sqlite3 and you must have added the folder name to your envirnment PATH or explicitly navigated to the folder before trying to run the program.
You do not need to specify any parameters, connection to a databse can be done from within the shell.
Installing the SQLite ODBC connector
The SQLIte main site at https://sqlite.org/ does not provide a download for an ODBC connector. A Google search will provide other sites that do. One freely available SQLite ODBC connector is available at http://www.ch-werner.de/sqliteodbc/. You should download the sqliteodbc.exe file. The file is a self contained Windows installer which you can run by double clicking it. You will however need Admin rights on the machine to perform the install.
This is a 32bit ODBC connector so it is assumed that you are using a 32bit version of Excel. A 64bit version of the driver is available from the Werner site should you need it.
You can check that the driver has been successfully installed by typing ODBC into the Windows start search panel and then selecting ‘ODBC DataSources (32 bit)’
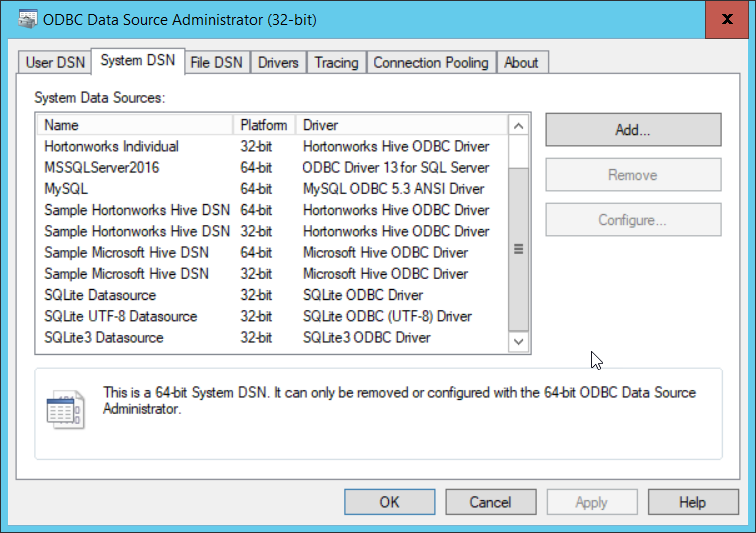
At the bottom of the list in the ‘system DSN’ tab youshould see the entry for the ‘SQlite3 datasource’.