Learning Objectives
Following this assignment students should be able to:
- integrate programing fundamentals and working with data
- solve a data analysis problem with logical and automated code chunks
- communicate effectively with informative and well-styled R scripts
Reading
-
Topics
- Style
- Organization
- Debugging
- Building up complex programs
-
Readings
Lecture Notes
Exercises
Format the Code (20 pts)
Programming computers to do cool science is a major advantage for modern scientists. But, developing research programs that are transparent, collaborative and reproducible is a major advantage for science. All data scientists can contribute to this goal by writing their code in easily readable, well described, and well commented scripts.
This script, which evaluates tree composition in a Michigan swamp, doesn’t follow good style. It works, but it’s difficult to understand exactly what it is doing.
- Download the script.
- Take a minute to understand what is going on.
- Modify the code so that it still does the same thing, but is easier to read because it has better style.
Dinosaur Size Distribution (40 pts)
This is exercise builds on Size Estimates by Name.
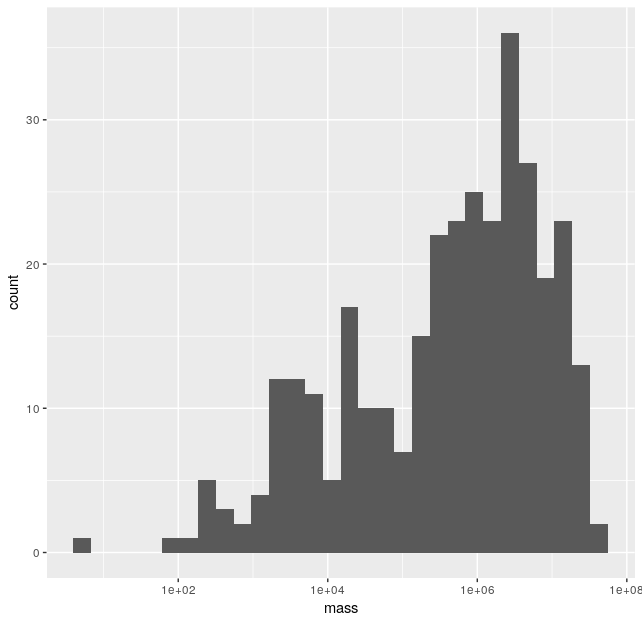
You want reproduce the analysis determining the distribution of body masses was for dinosaurs originally performed by Gorman & Hone 2012. Gorman & Hone (2012) use femur length (FL; the length of the upper leg bone) to estimate mass based on a general power law equation
Mass = a * FL ^ band the parameters vary by group:- Ornithischia:
a=0.002andb=3.0587 - Sauropodomorpha:
a=0.509andb=2.3459 - Theropoda:
a=0.0007andb=3.1854
Download the data, estimate the mass of each species, and then make a histogram of these masses with a logarithmically scaled size axis to reproduce their Figure 2a.
This should be done in a maximally automated way. The equations listed above should only need be entered once and the code should automatically use the right set of parameters based on the
Expected outputs for Dinosaur Size Distribution: 1Cladedata to estimate the mass of each species.- Ornithischia:
Cocili Data Exploration (40 pts)
Understanding the spatial distribution of ecological phenomena is central to the study of natural systems. A group of scientists has collected a dataset on the size, location, and species identify of all of the trees in a 4 ha site in Panama call “Cocoli”.
Download the Cocoli Data and explore the following spatial properties.
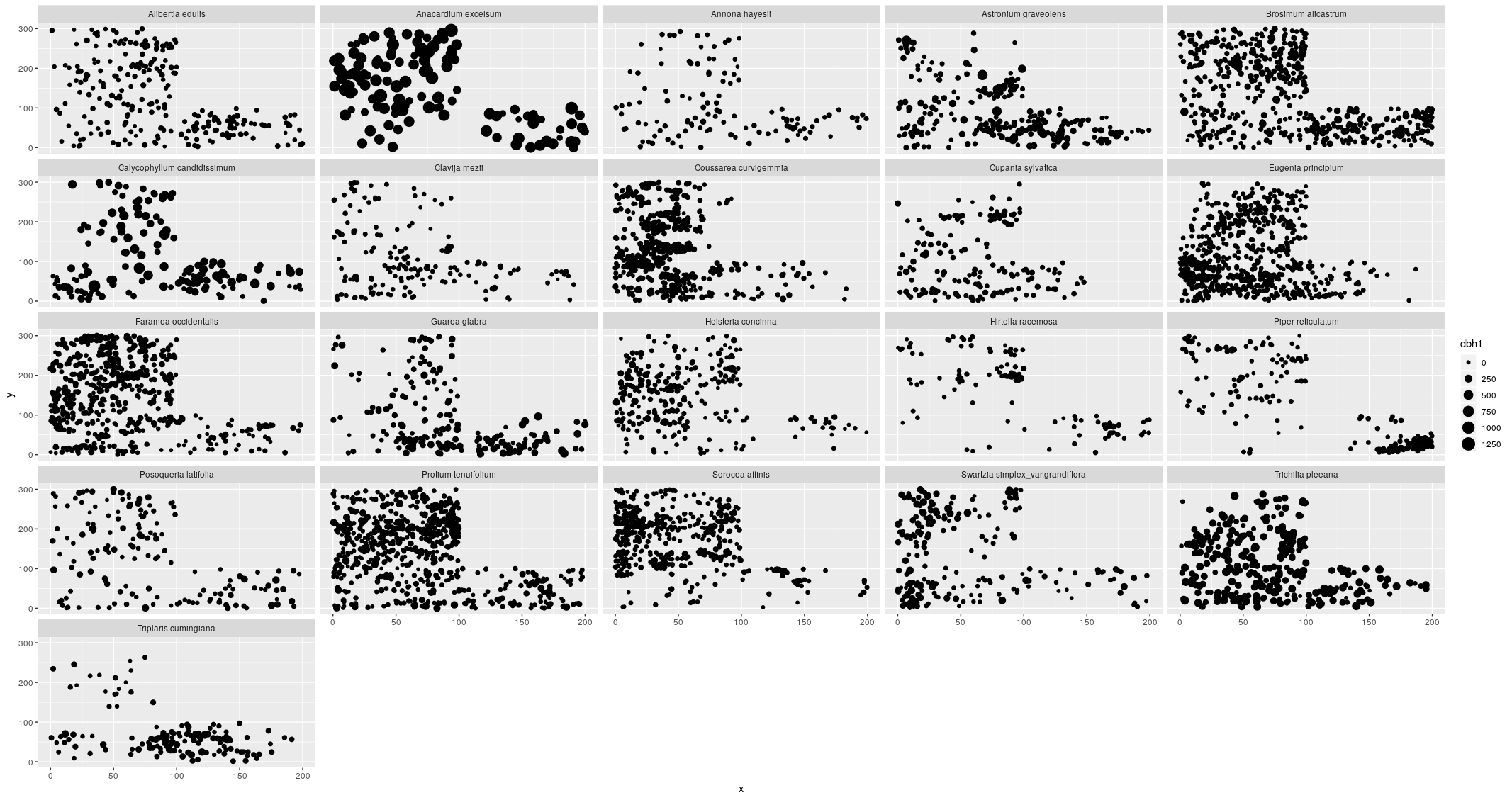
- Make a single plot showing the location of each tree for all species with
more than 100 individuals. Each species should be in its own subplot (i.e.,
facet). Label the subplots with the genus and species names, not the species
code. Scale the size of the point by its stem diameter (use
dbh1) so that larger trees display as larger points. Have the code save the plot in afiguresfolder in your project. - Basal area is a common measure in
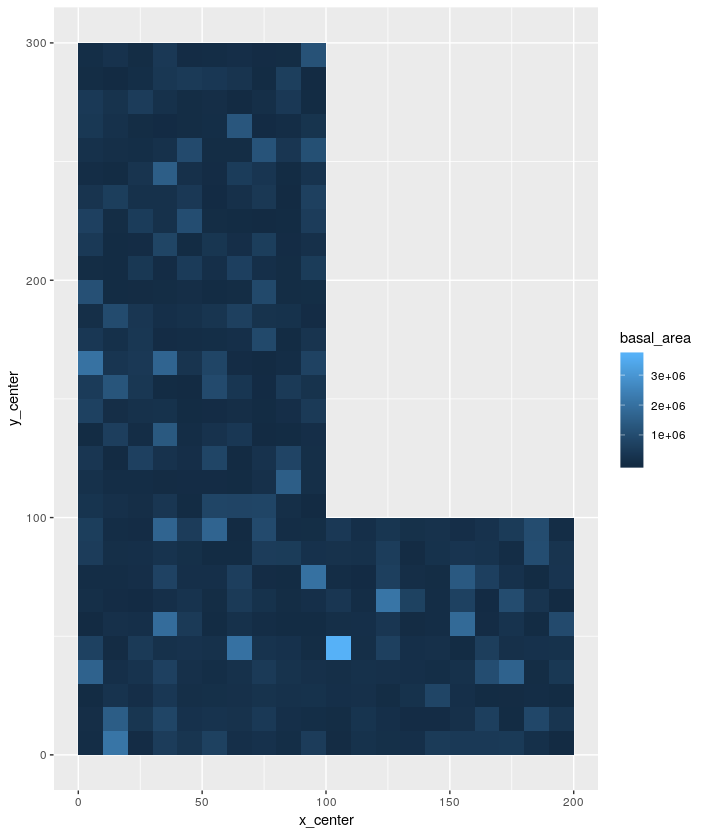
forest management and ecology. It is the sum of the cross-sectional areas of
all of the trees occuring in some area and can be calculated as the sum of
0.00007854 * DBH^2 over all of the trees. To look at how basal area varies
across the site divide the site into 100 m^2 sample regions (10 x 10 m cells)
and determining the total basal area in each region. I.e., take all of the
trees in a grid cell where x is between 0 and 10 and y is between 0 and 10
and determine their basal area. Do the same thing for x between 0 and 10 and
y between 10 and 20, and so on. You can do this using two “nested” for loops
to subset the data and calculate the basal area in that region. Make a plot
that shows how the basal area varies spatially. Since the calculation is for
a square region, plot it that way using
geom_tile()with the center of the tile at the center of the region where basal area was calculated. Have the code save the plot in afiguresfolder in your project.
- Make a single plot showing the location of each tree for all species with
more than 100 individuals. Each species should be in its own subplot (i.e.,
facet). Label the subplots with the genus and species names, not the species
code. Scale the size of the point by its stem diameter (use
Length of Floods (optional)
You are interested in studying the influence of the timing and length of small scale flood events on an ecosystem. To do this you need to determine when floods occurred and how long they lasted based on stream gauge data.
Download the stream guage data for USGS stream gauge site 02236000 on the St. Johns River in Florida. Find the continuous pieces of the time-series where the stream level is above the flood threshold of 2.26 feet and store the information on the start date and length of each flood in a data frame.
Expected outputs for Length of Floods: 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}